Раздел 6. Управление внешней памятью
6.1. Общие принципы управления внешней памятью
6.1.1. Причины необходимости управления
внешней памятью
Управление внешней памятью, под которой понимаются
дисковые устройства, относится к шестому уровню иерархической модели
операционной среды, следующему за уровнем управления процессами.
Такое соотношение уровней имеет место потому, что управление дисковыми
устройствами осуществляется элементарными процессами, выполняющимися и
взаимодействующими между собой в полном соответствие с принципами уровня 5.
Мы не будем подробно останавливаться на управлении
дисковыми устройствами, полагая, что этот материал больше относится к
специалистам по вычислительной техники.
Кратко же остановимся
на нем по двум причинам.
1.
Чтобы не игнорировать
уровень модели операционной среды и сохранить системность ее описания;
2. Чтобы дать общее представление о проблемах,
возникающих при управлении дисковыми устройствами, и методах их решения.
Отметим также, что в многозадачных системах, где
достаточно вероятны одновременные запросы нескольких процессов к одному
дисковому устройству, выбор рациональных алгоритмов управления дисковыми
устройствами может благоприятно повлиять на эффективность функционирования всей
системы.
Мы проведем обзор двух
классов дисковых устройств:
- диски с фиксированными головками чтения/записи;
- диски с подвижными
головками чтения/записи.
Качество устройств
первого класса выше, но и стоимость их также выше.
Далее мы рассмотрим особенности организации каждого из устройств.
6.1.2. Диски с
фиксированными головками чтения/записи
Диск всегда организован в
виде дорожек и секторов.
В диске с фиксированными головками на каждую дорожку приходится одна
головка чтения/записи.
В таком диске отсутствует радиальное перемещение головок, что хорошо, поскольку
радиальное перемещение является наиболее технологически трудоемким видом
перемещения.
Работой диска управляет программа, называемая
драйвером диска.
Прикладные процессы обмениваются данными с диском, делая запросы к
драйверу.
Запрос включает в себя:
- направление передачи;
- адрес на диске;
- адрес в оперативной
памяти.
В многозадачной системе запросов может быть много, поэтому они
устанавливаются в очереди запросов.
Существует два способа формирования очередей запросов
к диску.
- Одна очередь, когда все
запросы обрабатываются в порядке их поступления.
- Своя очередь для
каждого сектора диска. Запросы переупорядочиваются и обслуживаются с
учетом текущего состояния диска.
При этом возможно уменьшение среднего времени обслуживания запросов.

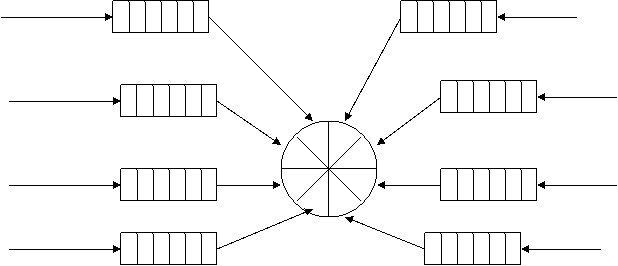
Диск, использующий второй способ управления,
называется страничным диском, потому что широко используется для управления
страничной памятью.
Если обозначить:
N - количество
секторов на дорожке;
R - время одного
оборота диска; (R/N – время прохождения сектора над головкой)
l - интенсивность поступления запросов;
W - среднее время
обслуживания запроса,
то для двух указанных
алгоритмов управления запросами приводятся следующие зависимости W от l:

Т.е. для страничного диска резкое ухудшение качества обслуживания с
ростом интенсивности запросов наступает существенно позднее, чем для диска с
одной очередью.
Коэффициент N/2 является мерой выигрыша при переходе от одной очереди к
организации очередей по секторам.
6.1.2. Диски с
подвижными головками чтения/записи
В дисках с подвижными головками существует
дополнительное к вращательному радиальное перемещение для поиска нужной
дорожки.
Т.е. время поиска складывается из времени поиска сектора и времени
поиска дорожки.
Радиальное перемещение трудоемко и требует
значительных затрат времени по сравнению с вращательным движением.
Поиск сектора выполняется по алгоритмам, похожим на алгоритм
страничного диска, т.е. запросы к секторам переупорядочиваются и обслуживаются
по мере прохождения секторов над головками.
Для поиска дорожки (или цилиндра - множества дорожек,
доступных без перемещения головок) существует целый ряд методов, которые
рассмотрены ниже.
Эти методы стремятся
минимизировать время поиска дорожки при определенных условиях.
- Первый пришел - первый
обслужен. FCFS – First Come – First
Served.
Справедливый метод, но очень неэффективен
с ростом нагрузки.
- Первым обслуживается
запрос с наименьшим расстоянием от текущего положения головки. SSTF - Shortest Seek Time First.
Метод не справедлив к запросам, которые далеки от текущего положения
головки. Возможно бесконечное откладывание таких запросов.
- Метод сканирования. SCAN. Для обслуживания выбирается запрос, ближайший в данном
направлении. Направление меняется, если головка достигла граничной дорожки
или нет запросов в данном направлении.
Это базовый метод работы с дисковыми устройствами.
- Циклическое
сканирование. CSCAN – Circular scan. Головки движутся от наружного цилиндра к внутреннему и по ходу
движения обслуживают запросы. После завершения движения головки скачком
возвращаются к наружному цилиндру и снова повторяют свое движение.
Это самая эффективная
стратегия.
- Развитие метода
сканирования. N-step scan. В процессе движения головки в данном направлении обслуживаются
только те запросы, которые появились к моменту начала движения в данном
направлении. Запросы, которые появились после начала движения в данном
направлении, группируются и обслуживаются на следующем проходе.
Исследования показали, что при малых интенсивностях запросов
эффективной является стратегия сканирования, а при большой интенсивности -
стратегия циклического сканирования в сочетании с распределением запросов по
секторам.
Выводы:
1. Нагрузки на диск растут с увеличением степени
многозадачности. В этом случае становится целесообразными использование
рациональных стратегий поиска.
2. Увеличение числа дисковых устройств не всегда может
решить проблему из-за свойства локализации запросов, т.е. большого числа
запросов к малому числу дисков.
3. Неравномерность запросов снижает эффективность перечисленных
выше стратегий, т.к. они оптимизированы при допущении равномерности запросов.
4.
Сложность
файловой системы может служить причиной низкой эффективности поиска данных на
дисковых устройствах.
6.2. Системное ПО для управления внешней памятью
6.2.1. Правила ввода-вывода на диски
Назовем вводом-выводом всякую
передачу информации между диском и совокупностью (процессор, память).
Схема организации ввода-вывода
представлена на рисунке.
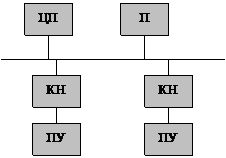
ЦП
– центральный процессор; П – память; КН – контроллер; ПУ – периферийное
устройство.
Контроллер представляет собой устройство
управления периферийными устройствами определенного типа.
Контроллер предлагает интерфейс
взаимодействия с ним, которым пользуется программа управления периферийным
устройством, называемая драйвером.
Базовой операцией всегда
является передача между участком памяти и периферийным устройством:
ПРОЧИТАТЬ(АДР_ПАМ, АДР_УСТР);
ЗАПИСАТЬ(АДР_ПАМ, АДР_УСТР);
Кроме того, обязательной является
операция:
ТЕСТ(АДР_УСТР);
результатом которой в
самом минимальном случае являются следующие значения:
ГОТОВ – устройство готово к работе;
КОНЕЦ – операция завершена;
ОШИБКА – во время операции произошла ошибка.
Кроме того, операции обмена могут
быть организованы как синхронные или как асинхронные.
В синхронной операции выполняется следующий цикл:
ЦИКЛ:
ТЕСТ(УСТР);
if ùКОНЕЦ then begin
goto ЦИКЛ;
end;
В асинхронной операции
используется система прерываний. Сигнал прерывания оповещает об окончании
операции. Прерывания позволяют выполнять параллельную обработку.
С этих позиций и будем рассматривать операции управления диском.
Поскольку диск делится на
дорожки и секторы, при этом, сектор определяет передаваемую единицу информации,
то адрес на диске имеет вид: (№ дисковода, № дорожки, № сектора).
Интерфейс драйвера состоит
из трех функций:
ВЫБРАТЬ_ДИСКОВОД(№ ДИСКОВОДА) – выделяет текущий дисковод, с которым происходит весь
последующий обмен информацией.
ПРОЧИТАТЬ_СЕКТОР(№ ДОРОЖКИ, № СЕКТОРА, КУДА) – передает информацию из сектора диска в память,
«куда» - адрес памяти.
ЗАПИСАТЬ_СЕКТОР(№ ДОРОЖКИ № СЕКТОРА, ОТКУДА) – передает информацию из памяти («откуда») на диск.
Пусть, например, диск содержит Д дорожек по С секторов и в каждом
секторе хранится по Б байтов.
При обменах с диском используется буферизация, что важно для часто
встречающихся последовательных обращений.
В частности, удобно читать содержимое всей дорожки сразу, т.к. в этом
случае для всех секторов дорожки возникает лишь одна задержка, связанная с
поиском нужной дорожки.
Таким образом, можно зарезервировать N буферов объема одной дорожки - С*Б байтов. Число N может
меняться и определяется при генерации системы.
Чтение. Допустим, необходимо прочитать сектор НСЕКТ на дорожке НД.
Если один из буферов содержит дорожку НД, то чтение происходит без
обращения к диску с использованием соответствующего участка из буфера.
Иначе, следует предварительно загрузить содержимое дорожки НД из диска
в буфер.
Запись. Для уменьшения числа обращений к диску, буфер
копируется на диск как можно позже.
Допустим, надо произвести запись в НСЕКТ сектор дорожки НД.
Если дорожка НД есть в буфере, то соответствующий сектор изменяется и
на этом операция заканчивается, если только это не «непосредственная запись».
Если же дорожка НД не представлена, то она должна быть предварительно
скопирована в буфер, после чего операция сводится к предыдущей операции.
За исключением «непосредственной записи», буфер копируется на диск в одном
из двух случаев:
- когда он переназначается
для загрузки новой дорожки в память в соответствии с алгоритмом
переназначения;
- когда происходит
очистка буфера, вызванная закрытием файла.
Алгоритм переназначения буферов основан на свойстве локальности ссылок.
Вероятность обращения к некоторой информации тем больше, чем ближе по времени
ее предыдущее использование.
Таким образом, буферы хронологически упорядочиваются по времени
последних обращений к ним.
Если нужен новый буфер, то он выбирается по следующему порядку с
убывающим предпочтением:
- свободный буфер;
- занятый буфер, но не
изменявшийся со времени заполнения;
- буфер среди оставшихся
буферов, который имеет самую позднюю ссылку на обращение к нему.
В случаях 1 и два выбранный буфер может быть сразу использован, а в
случае 3 его содержимое должно быть предварительно скопировано на
соответствующую дорожку.
6.2.2. Принципы программирования процедур управления
диском
Рассмотрим случай одного буфера
(N = 1), объем которого равен одной дорожке.
С буфером связано два признака:
- ДОР_ЗАГР – номер
загруженной дорожки (0, если пусто);
- ИЗМ – ИСТИНА, если
содержимое буфера изменялось после загрузки.
Интерфейс контроллера предлагает следующие функции:
- ВЫБРАТЬ_ДИСКОВОД(ДВД) – выбирает дисковод в качестве рабочего
устройства;
- НАЙТИ_ДОРОЖКУ(НД) – подводит головку чтения-записи к дорожке нд;
- ПЕРЕДАТЬ_СЕКТОР(АДР, НД,
НСЕКТ, НАПР) – передает
содержимое между сектором НС текущей дорожки, и памятью, начиная с адреса
АДР, в зависимости от направления (чтение, запись);
- ПЕРЕДАТЬ_ДОРОЖКУ(НД, АДР,
НАПР) –
передает содержимое между дорожкой и памятью, в зависимости от
направления;
- ТЕСТ() – позволяет проверить признаки ГОТОВ, КОНЕЦ,
ОШИБКА в слове состояния контроллера.
Процедура:
ЗАПИСАТЬ_СЕКТОР(№
ДОРОЖКИ, № СЕКТОРА, ОТКУДА)
будет включать
параметр РЕЖИМ,
который может принимать следующие значения:
- нормальная_запись
- непосредственная_запись
- первая_запись
procedure ПРОЧИТАТЬ_СЕКТОР(НД, НСЕКТ, КУДА);
begin
if НД <> ДОР_ЗАГР then begin
if ИЗМ then begin
ПЕРЕДАТЬ_ДОРОЖКУ(ДОР_ЗАГР, БУФЕР,
ЗАП);//записать дорожку из
//буфера
на диск
end_if;
ПЕРЕДАТЬ_ДОРОЖКУ(НД,БУФЕР,ЧТЕН);//загрузить
дорожку с диска в буфер
end_if;
КОПИРОВАТЬ(КУДА, БУФЕР[НСЕКТ]);
end_procedure;
procedure ЗАПИСАТЬ_СЕКТОР(НД, НСЕКТ, ОТКУДА,
РЕЖИМ);
begin
if НД <> ДОР_ЗАГР then begin
if ИЗМ then begin
ПЕРЕДАТЬ_ДОРОЖКУ(ДОР_ЗАГР, БУФЕР,
ЗАП);//записать дорожку из
//буфера на диск
end_if;
if РЕЖИМ = ПЕРВАЯ_ЗАПИСЬ then begin//данных нет на диске
ДОР_ЗАГР := НД;//назначается
свободная дорожка
end else begin//дорожка
есть на диске, считываем ее
ПЕРЕДАТЬ_ДОРОЖКУ(НД, БУФЕР, ЧТЕН);
end_if;
end_if;
КОПИРОВАТЬ(БУФЕР[НСЕКТ], ОТКУДА);//копирование
из адреса в буфер
if РЕЖИМ =
НЕПОСРЕДСТВЕННАЯ_ЗАПИСЬ then begin
ПЕРЕДАТЬ_СЕКТОР(БУФЕР[НСЕКТ],НД,НСЕКТ,ЗАП);//записать сектор на диск
end else begin
ИЗМ := ИСТИНА;
end_if;
end_procedure;
procedure ПЕРЕДАТЬ_ДОРОЖКУ(НД, БУФЕР, НАПРАВЛЕНИЕ);
begin
НАЙТИ_ДОРОЖКУ(НД);
M: ТЕСТ();
if ùКОНЕЦ then begin
goto M;
end_if
for НСЕКТ := 0 to КСЕКТ-1 do begin
ПЕРЕДАТЬ_СЕКТОР(БУФЕР[НСЕКТ], НД, НСЕКТ,
НАПРАВЛЕНИЕ);
end_for;
ИЗМ := ЛОЖЬ;
if НАПРАВЛЕНИЕ = ЧТЕН then begin
ДОР_ЗАГР := НД;
end_if;
end_procedure;
procedure ПЕРЕДАТЬ_СЕКТОР(АДР, НД, НСЕКТ,
НАПРАВЛЕНИЕ);
begin
НСЕКТ = СООТВ(НСЕКТ);//найти физический номер
сектора
НПОПЫТКИ := 0;
СНОВА:case НАПРАВЛЕНИЕ of
ЧТЕН: ПРОЧИТАТЬ_СЕКТ(АДР, НД, НСЕКТ);
ЗАП:
ЗАПИСАТЬ_СЕКТ(АДР, НД, НСЕКТ);
end_case;
М: ТЕСТ();
if ОШИБКА then begin
НПОПЫТКИ := НПОПЫТКИ + 1;
if НПОПЫТКИ < НМАКС then begin
goto СНОВА;
end else begin
ПРИЧИНА := ФАТАЛЬНАЯ_ОШИБКА;
ВОЗБУДИТЬ_ИСКЛЮЧЕНИЕ;
end_if;
end_if;
if ùКОНЕЦ then begin
goto М;
end_if
end_procedure;
В случае сбоя передачи операция повторяется. Если ошибка, приводящая к
сбою продолжает повторяться, то после НМАКС попыток драйвер осуществляет
прерывание программы с выдачей сообщения об ошибке.
Как видно, существуют
еще более низкоуровневые функции:
ПРОЧИТАТЬ_СЕКТ(АДР,
НД, НСЕКТ);
ЗАПИСАТЬ_СЕКТ(АДР,
НД, НСЕКТ);
которые реализуются в
самом контроллере диска и на основе которой реализуется процедура ПЕРЕДАТЬ_СЕКТОР(АДР,
НД, НСЕКТ, НАПР).
6.3. Управление внешней памятью в современных ОС
6.3.1. Терминология
- Диск –
физическое устройство внешней памяти (жесткий диск, дискета,
компакт-диск).
- Диск делится на секторы, блоки фиксированного размера.
- Раздел –
набор непрерывных секторов на диске. Адрес начального сектора раздела,
размер, хранятся в таблице разделов.
- Простой том – объект, представляющий секторы одного раздела, которым драйверы
управляют как единым целым.
- Составной том – объект, представляющий секторы нескольких разделов, которыми
драйверы управляют как единым целым.
Существуют диски базовые и динамические.
Базовый диск – это диск, созданный по схеме разделов MS DOS.
Поддержка разбиения дисков на
разделы по схеме MS DOS имеет следующие недостатки:
- Внесение изменений в
конфигурацию требует перезагрузки системы, что нежелательно для серверов;
- Информация о
конфигурировании томов хранилась в реестре, что затрудняло перенос дисков.
- Проблемы с
ограничением на имена дисков из диапазона A – Z.
Динамические диски поддерживают составные тома. При этом данные о
составных томах хранятся на самих дисках. Это облегчает перенос дисков между
системами. Кроме того, динамические диски могут расширяться.
Существует различие между
загрузочным томом и системным томом.
Системный том содержит загрузчик,
Загрузочный том содержит системные файлы.
Диск может иметь четыре главных
раздела, один из которых должен быть активным.
MBR (master
boot record) –
загрузочный код, находящийся в первом секторе диска, содержит таблицу разделов,
состоящую из четырех элементов.
MBR считывает код из первого сектора активного раздела и
передает ему управление.
6.3.2. Структура динамического диска
За поддержку динамических дисков
отвечает диспетчер логических дисков ДЛД (Logical Disk Manager – LDM).
База данных ДЛД размещается в
зарезервированном пространстве в конце каждого ДД.
ДЛД реализует и таблицу разделов
в стиле MS DOS,
чтобы:
- унаследованные утилиты
могли работать с диском;
- загрузочный код мог
найти загрузочный и системный тома, если они находятся на динамических
дисках (ДД).

Загрузочная
запись
Область разделов База
данных ДЛД
Внутренняя
организация динамического диска
База данных ДЛД состоит из
четырех областей.
- Сектор заголовка
- Таблица оглавления
- Записи базы данных
- Журнал транзакций
![]()
Структура
базы данных ДЛД
Сектор заголовка содержит 128-битовое число ID – идентификатор
диска и имя дисковой группы, которое формируется конкатенацией имени компьютера
и строки Dg0.
Таблица оглавления содержит
информацию о структуре базы данных.
Элементы базы данных могут быть
четырех типов:
- раздел
- диск
- компонент
- том
Журнал транзакций хранит резервную копию информации базы данных в
процессе ее изменения.
6.3.3. Типы составных томов
Существуют следующие типы
составных томов:
- перекрытые (spanned)
- чередующиеся (striped)
RAID-0
- зеркальные (mirrored) RAID-1
- RAID-2 не используется (n дисков
с данными, n-1 дисков контроль ошибок)
- RAID-3 похож на RAID-2, но 1 диск для контроля
- RAID-4 похож на RAID-3, но блоки имеют размер, больший, чем байт.
- RAID-5 – самый
распространенный
- RAID-6 похож на RAID-5, но имеет два диска для контроля
- RAID-7 сложный.
- Комбинации, например, RAID 1+0, 3+0,
5+0, 5+1.
Управление составными томами существенно сложнее, т.к. их разделы могут
быть несмежными и даже находиться на разных дисках.
Перекрытые тома
Перекрытый том – это единый логический том, состоящий
из нескольких свободных разделов на одном или нескольких дисках.
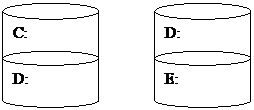
Перекрытый том D:
Перекрытый том удобен для объединения небольших
областей свободного дискового пространства в единый том большего объема.
Если том отформатирован для NTFS, его можно расширять.
Диспетчер томов скрывает
физическую конфигурацию дисков от файловой системы.
Чередующиеся тома
Чередующийся том – это группа разделов, каждый из которых размещается
на отдельном диске и объединяется в один логический том. Другое название – RAID-0.
Файловой системе этот чередующийся том кажется обычным томом, но
диспетчер томов оптимизирует хранение и выборку данных, распределяя их между
физическими дисками.
Данные равномерно распределяются между дисками, а поскольку к данным на
разных дисках можно обращаться одновременно, быстродействие ввода-вывода часто
возрастает.
Задача повышения надежности
хранения данных не ставится.

Логическая нумерация
секторов в чередующемся томе
Зеркальные тома
В зеркальном томе содержимое
раздела на одном диске дублируется в разделе равного размера на другом диске.
Другое название RAID-1.
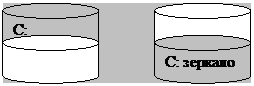
Зеркальный том
Когда программа что-то пишет на
диск С:, диспетчер томов пишет те же данные в идентичный участок зеркального
раздела.
Если первый диск окажется
поврежденным, то диспетчер автоматически обратится за данными к зеркальному
разделу.
Быстродействие операций чтения
возрастает, т.к. диспетчер распределяет их между томами.
Хотя запись приходится вести на
два диска, но из-за асинхронности операций записи быстродействие записи почти
не снижается.
Тома RAID-5
Том RAID-5 – это
отказоустойчивый вариант обычного чередующегося тома. Том также называют
чередующимся томом с записью четности (striped volumes with parity).
Информация о четности для
чередующейся области 1 хранится на диске 1. Она представляет собой побайтовую
логическую сумму (XOR) чередующихся областей 1
дисков 2 и 3.
Информация о четности для
чередующейся области 2 хранится на диске 2.
Информация о четности для
чередующейся области 3 хранится на диске 3.
Чередование областей четности
между дисками оптимизирует операции ввода-вывода.
Когда данные записываются на
какой-нибудь из дисков, байты четности должны быть пересчитаны и перезаписаны.
Если бы информация о четности
хранилась на одном диске, то к нему все время шли бы обращения.
При сбое диска 1 содержимое его
областей 2 и 5 вычисляется побайтовым логическим сложением соответствующих
чередующихся областей на диске 3 с областями четности на диске 2.
Содержимое чередующихся областей
3 и 6 определяется побайтовым сложением соответствующих областей на диске 2 с
областями четности на диске 3.
Для организации тома требуется,
по крайней мере, три диска.
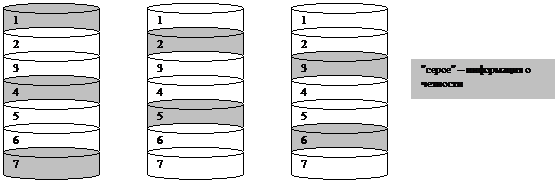
Том
RAID-5
6.3.5. Ввод-вывод на томах
Драйверы устройств внешней
памяти соответствуют архитектуре "класс-порт-минипорт".
Согласно этой архитектуре драйвер класса внешней памяти реализует общую
функциональность для всех устройств внешней памяти.
Порт-драйвер реализует функциональность, общую для конкретной шины,
например, SCSI или IDE.
Минипорт-драйвер реализует интерфейс с конкретным устройством.
Пример класс-драйвера диска –
драйвер Disk.sys (каталог winnt\system32\drivers\).
Пример порт-драйвера диска –
драйвер Pciidex.sys, для IDE диска.
Иногда порт-драйвер и
минипорт-драйвер представлены одним объектом, например, Atapi.sys.
Управление базовыми дисками
осуществляет драйвер FtDisk.sys.
Управление динамическими дисками осуществляет драйвер Dmio.sys.
Драйверу файловой системы
требуется поддержка диспетчера томов для взаимодействия с драйвером устройства.
Обращение драйвера файловой
системы к диску, которому администратор назначил, например, букву D:, перехватывается диспетчером томов, который по своим
таблицам корректирует параметры запроса перед тем, как передать его драйверу
устройства.
Запрос корректируется так, чтобы
он ссылался на нужное смещение относительно начала физической области,
соответствующей логической области.
Если запрос затрагивает два
раздела, то генерируется дополнительный запрос к другому диску.
Этапы выполнения
ввода-вывода:
- Драйвер файловой
системы инициирует ввод-вывод на уровне секторов
- Диспетчер ввода-вывода
перенаправляет запрос диспетчеру томов
- Диспетчер томов определяет,
какому разделу чередующегося тома адресован запрос и создает новый запрос
к диску, на котором расположен нужный раздел
- Диспетчер ввода-вывода
направляет запрос драйверу устройства
- Драйвер устройства
выполняет аппаратное обращение к диску.
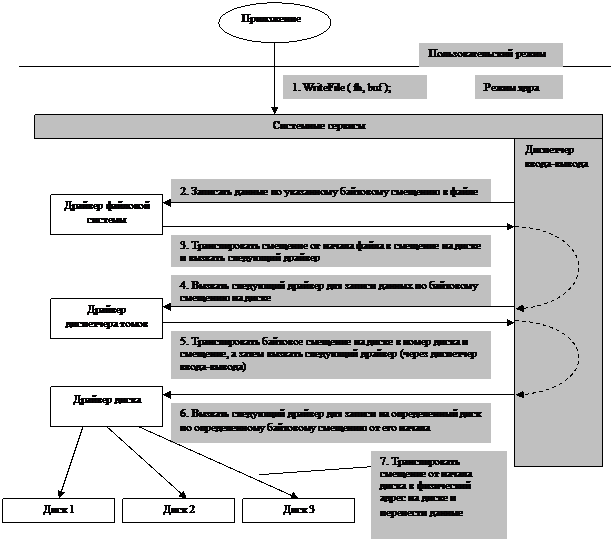
Схема
ввода-вывода
Заключение по разделу 6
В данном разделе были рассмотрены следующие вопросы:
- Общие принципы
управления внешней памятью;
- Системное программное
обеспечение для управления внешней памятью;
- Управление внешней
памятью в современных операционных системах.
Раздел 7. Системное программное
обеспечение для управления файлами
7.1. Общая характеристика системы управления файлами
7.1.1. Понятия и определения
Система управления файлами (файловая система) – это
программное обеспечение, которое отвечает за создание, уничтожение,
организацию, чтение, запись, модификацию и перемещение файловой информации, за
управление доступом к файлам и за управление ресурсами, которые используются
файлами.
Система управления файлами – это часть системы
управления всей памятью, исходно ответственная за управления файлами на дисковых
носителях. Она ответственна за обеспечение средств персонального хранения данных,
а также за разделение данных между пользователями.
Система управления файлами – это часть ОС, которая
обеспечивает сохранение файлов и реализует функции доступа.
Файл – это поименованный набор
данных. Он обычно хранится на устройствах вторичной памяти, таких как диски,
ленты. Файл является объектом: он обладает именем и снабжен функциями доступа.
С точки зрения файловой системы
файлами можно манипулировать как целыми объектами посредством следующих
операций:
- Открыть
- Закрыть
- Создать
- Уничтожить
- Скопировать
- Переименовать
Но также можно и манипулировать
отдельными элементами каждого файла посредством операций:
- Прочитать
- Записать
- Обновить
- Вставить
- Удалить
Вообще с целью более осознанного освоения файловой
системы целесообразно представлять общую иерархию данных в системе. Такая
иерархия выглядит следующим образом:
- Отдельные биты
- Порции байта
(полубайты)
- Байты (символы, числа)
- Поля из групп байтов
(строки, числа)
- Записи (группы
полей), ключ – управляющее поле, уникально идентифицирующее запись
- Файл – группа
записей
- База данных – группа
связанных файлов
7.1.2. Функции
системы управления файлами
Пользователи организуют информацию
в файлах в соответствии с логической организацией. В машине файлы хранятся в
соответствии с физической организацией.
Система управления файлами
преобразует представление логической организации в физическую и наоборот.
Перечислим основные функции
системы управления файлами:
- Файловая система должна
предоставить пользователю возможность создавать, модифицировать и удалять
файлы;
- Файловая система
должна предоставить пользователям возможность разделять общие файлы
тщательно управляемым способом;
- Файловая система
должна предоставить разнообразные механизмы разделения, при которых
обеспечиваются различные типы управляемого доступа, такие как: доступ к
чтению, доступ записи, доступ к выполнению, и разные их комбинации
- Файловая система
должна предоставить пользователю возможность структурировать файлы
способом, самым подходящим для каждого приложения;
- Файловая система
должна предоставить пользователю возможность передавать информацию между
файлами;
- Файловая система
должна обеспечить сохранение и восстановление файлов для предотвращения
случайных потерь или разрушения информации;
- Файловая система
должна предоставить пользователю возможность обращаться к файлам по их
символическим именам, а не по именам физических устройств;
- Файловая система
должна обеспечивать шифрование и дешифрование в особых случаях, связанных
с банковскими, медицинскими, юридическими делами
- Файловая система
должна иметь дружественный интерфейс, давая пользователю логический взгляд
на данные, а не физический взгляд
7.1.3. Компоненты системы управления файлами
Компоненты системы управления
файлами могут быть выделены при изучении "пути", который проходит
типичный запрос к файловой системе, порождаемый на уровне файла.

В общем, каждая
файловая система содержит следующие средства:
- Средства управления
файлами;
- Средства доступа к
файлам;
- Средства управления
выделением памяти;
- Средства сохранения
целостности файлов.
7.1.4. Иерархическая модель файловой системы
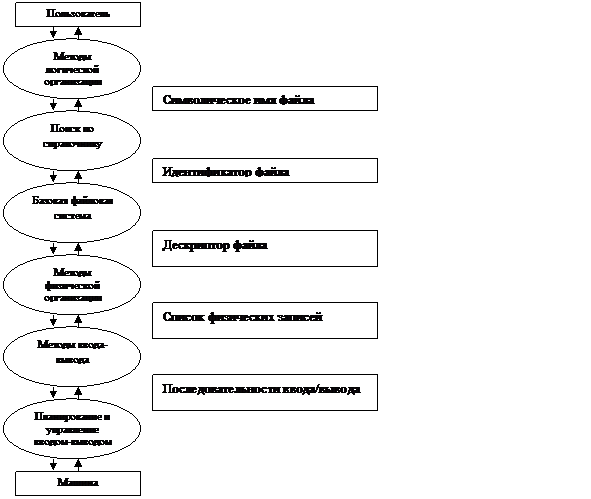
Система управления файлами реализует
соответствие между логической и физической организациями файлов. Это две разные
организации, каждая из которых определяется собственными структурами данных.
Система управления файлами строится
по иерархической схеме из двух уровней – всякое действие, определяемое на
логическом уровне, интерпретируется некоторой совокупностью действий на
физическом уровне.
Чтобы отделить логическую
организацию от физической организации, целесообразно ввести промежуточную
организацию, играющую роль интерфейса.
Установление соответствия между
логической и физической организациями происходит в два этапа:
- Перевод имен,
входящих в функции доступа, в логические адреса
- Перевод логических
адресов в физические адреса
Т.о. общая схема организации СУФ может выглядеть
следующим образом:
|
Внешние имена |
Интерпретация имен |
|
Внутренние имена |
Реализация логических
функций доступа |
|
Логические адреса |
Реализация физических
функций доступа |
|
Физические адреса |
Размещение во внешней
памяти, реализация физического ввода-вывода |
Основными
операциями файловой системы являются:
- Отображение запросов
на доступ из виртуального в реальное файловое пространство
- Передача элементов
между файловой и оперативной памятью
Изучение
этих операций требует определенного знания свойств реальных устройств хранения
файлов.
Устройства хранения файлов
обладают следующими характеристиками:
- Емкость
- Размер записи
- Метод доступа
- Сменяемость
- Скорость передачи
данных
- Задержка
- Время установки
- Относительная
стоимость
Все системы имеют набор справочников
(словарей, каталогов), которые идентифицируют и определяю местонахождение всех
файлов.
Элемент справочника содержит как
минимум имя и физический адрес файла или его дескриптора (или сам дескриптор).
Справочник – это тоже файл.
Наиболее общим видом организации
справочника является древовидная структура, в которой каждая вершина дерева
является файлом или справочником, а каждая ветвь указывает или на файл или на
справочник.
7.2. Архитектуры драйверов файловой системы
Существует два типа ДФС:
- Локальные, управляющие томами, подключенными
непосредственно к компьютеру
- Сетевые, позволяющие обращаться к томам на
удаленных компьютерах
7.2.1. Локальные ДФС
Упрощенная
схема взаимодействия локального ДФС с диспетчеров ввода-вывода и драйвером
устройства внешней памяти показана на схеме.
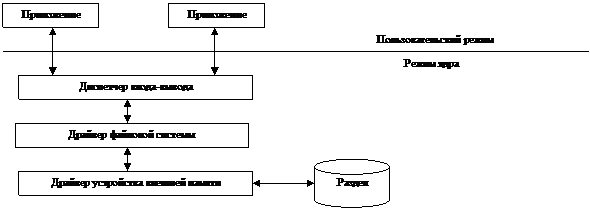
Локальный ДФС
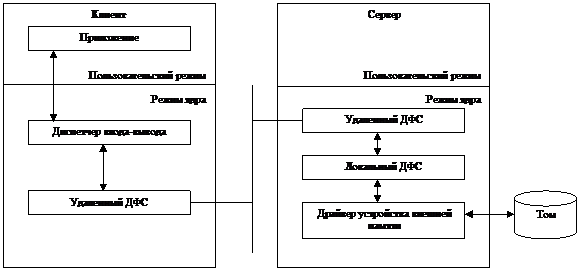
7.2.2. Удаленные ДФС
Удаленные
ДФС состоят из двух компонентов: клиента и сервера. Взаимодействие между ДФС на
клиентской и серверной сторонах показано на рисунке.
7.2.3. Пример - драйвер файловой системы NTFS
Место драйвера NTFS в общей
структуре системы ввода-вывода представлено на рисунке.
Это взаимодействие отражено на следующем рисунке.
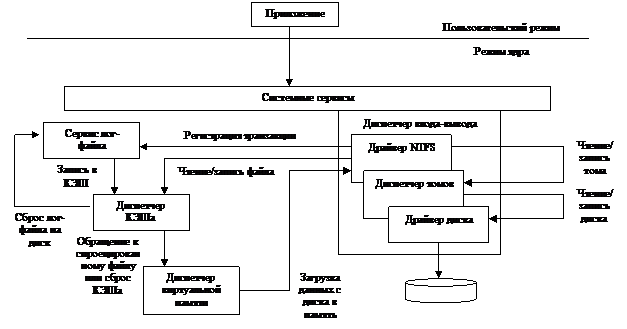
Драйвер взаимодействует
со следующими компонентами:
- Сервисом лог-файла
- Диспетчером КЭШа
- Диспетчером виртуальной памяти
При записи на
диски NTFS взаимодействует
с диспетчером томов, который поддерживает RAID-1 (зеркалирование)
и RAID-5 (чередование
с проверкой на четность).
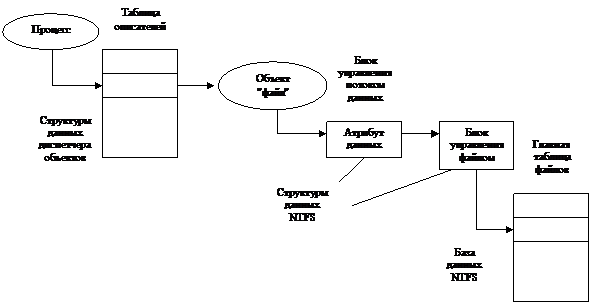
Структуры
данных NTFS представлены
на рисунке.
Таблица
описателей транслирует описатель, с которым работает приложение, в указатель на
объект "файл".
В
качестве одного из элементов данных объекта является блок управления потоком (stream control block SCB) для
атрибута, запрашиваемого процессом.
SCB содержит информацию о том, как
искать конкретные данные внутри файла, и указывает на блок управления файлом (FCB), который содержит указатель на запись о файле в
главной таблице файлов.
7.2.4. Работа драйвера файловой системы
Основной
способ доступа приложений к файлам – это вызов Win32-функций ввода-вывода.
Приложение
открывает файл с помощью CreateFile, затем
читает, записывает и закрывает его.
CreateFile формирует полное имя файла и
вызывает встроенную в Kernel32.dll функцию NtCreateFile.
Эта
функция выполняет разбор имени, по таблицам находит устройство, на котором
находится данный файл, и формирует запрос к драйверу этого устройства.
Драйвер
ищет указанный файл, проверяет права доступа и создает описатель объекта
"файл", который по цепочке возвращается назад в приложение в виде
результата, возвращаемого функцией CreateFile.
При
выполнении ReadFile системная
функция NtReadFile проверяет
права на чтение файла и если такие права есть, то формирует запрос к драйверу
файловой системы.
Если
файл может быть кэширован, драйвер копирует данные из диспетчера КЭШа в буфер,
указанный в функции ReadFile. Для
копирования используется функция CcCopyRead, которая
принимает в качестве параметров объект "файл", смещение внутри файла
и длину данных.
Если
запрашиваемых данных в КЭШе нет, то возникает ошибка, которая обрабатывается
функцией MmAccessFault.
В
результате обработке возникает еще один запрос к драйверу файловой системы, но
в котором уже явно указано, что данные должны быть считаны с диска. После
считывания данных управление возвращается потоку, вызвавшему функцию NtReadFile, но к этому моменту данные уже
есть в КЭШе.
Функция
WriteFile работает
аналогично.
7.3. Логическая и физическая
организация файлов
7.3.1. Логическая
организация файлов
7.3.1.1. Общие принципы логической организации файлов
Для спецификации логической организации файла
определим для него абстрактную структуру. Будем считать, что файл представляет собой
совокупность записей, с каждой из которых связано фиксированное число
атрибутов.
Атрибут определяется именем и
областью значений.
Пример
1:
Последовательный
файл символов. Каждая запись обладает следующими атрибутами:
(номер,
<целое число>)
(содержимое,
<символ ASCII>)
Атрибут
НОМЕР может существовать неявно.
Пример
2:
Файл
базы данных.
(ссылка,
<идентификатор работы>)
(автор,
<последовательность символов>)
(издатель,
< последовательность символов >)
(год,
<целое число>)
(тема,
< последовательность символов >)
Данная абстрактная структура была превращена в
конкретную структуру в файловой системе. А именно.
Каждый файл содержит набор атрибутов, который состоит
из последовательности байтов, называемой потоком данных.
Приложения могут создавать новые дополнительные
атрибуты в виде именованных потоков данных и обращаться к ним по именам.
Логическая организация файлов имеет дело с тем, каким образом
записи файла рассматриваются приложением, а физическая - каким образом хранятся
на дисковой памяти. В рамках приложения обычно рассматривается виртуальная
файловая память, в рамках доступа – физическая файловая память.
Цель концепции виртуальной файловой памяти –
предоставление единообразных принципов рассмотрения механизмов для размещения
информации.
Будем рассматривать файл как упорядоченную
последовательность элементов, имеющую символическое имя, где элемент – это
наименьшая адресуемая единица информации.
Элемент файла F, имеющий
порядковый номер е, адресуется парой
[F,e].
Обратим внимание на аналогию с
сегментной виртуальной памятью.
Виртуальный файл, являющийся
результатом логической организации, состоит из набора логических записей R0, R1,…, где запись
есть непрерывный блок информации, передаваемый во время операции чтения/записи.
Логическая запись – это набор данных, рассматриваемый
как единица с пользовательской точки зрения.
Аналогично, реальный файл,
являющийся результатом физической организации, делится на физические записи,
размер записи определяется характеристиками запоминающей среды.
Физическая запись или блок – это единица информации,
фактически читаемая с устройства или записываемая на устройство.
Физическая запись может состоять из нескольких
логических записей и наоборот.
Когда каждая физическая запись точно содержит одну
логическую запись, говорят, что файл состоит из необъединенных записей.
Когда каждая физическая запись
содержит несколько логических записей, говорят, что файл состоит из
объединенных записей.
С целью повышения эффективности ввода-вывода
физических записей используется средство, называемое буферизацией.
Буферизация позволяет выполнять
параллельный ввод-вывод. Оперативная память, содержащая несколько физических
блоков файла, называется буфером.
Самая общая схема называется
двойной буферизацией и работает следующим образом:
Существует два буфера.
Сначала
записи генерируются процессом и помещаются в первый буфер, пока он не
заполнится.
Тогда инициируется запись из
первого буфера на диск.
Пока это происходит, процесс
сохраняет записи во второй буфер.
Когда второй буфер заполнится и
когда передача из первого буфера закончится, начинается передача из второго
буфера.
Процесс в это время складывает
записи в первый буфер.
Такое переключение с одного
буфера на другой позволяет параллельно выполнять генерацию записей и сохранение
их на диске.
Дополнительно к буферизации используют очереди
запросов.
Методы доступа с организацией
очереди используются, когда последовательность, в которой записи
обрабатываются, может быть предсказана. Метод выполняет опережающую буферизацию
и планирование операций ввода-вывода. Эти методы стараются сделать следующую
запись доступной, пока обрабатывается предыдущая запись.
Базовые методы (без
использования очередей) используются, когда последовательность обработки
записей не может быть предсказана или не желаема самим пользователем.
7.3.1.2. Последовательная
организация
Последовательная организация – это разновидность
организации, при которой записи упорядочены, и доступ к ним производится в
последовательности, соответствующей упорядоченности. Если была считана запись Ri, то следующая доступная запись – это Ri+1. Внутри файла записи могут быть фиксированной или
переменной длины. В случае переменной длины непосредственно перед записью
должен быть указатель длины. Физически последовательная структура может быть
реализована или последовательно или с помощью указателей.
Единственной разрешенной для
использования функцией доступа является функция "следующий".
Если текущая запись не является
последней, то логический адрес следующей записи определяется выражением:
Адрес(текущий) +
размер(текущий)
7.3.1.3.
Индексная организация
Файл состоит из тех же записей, но надо получить
прямой доступ. Предполагается, чта каждая запись Ri имеет логическую идентификацию – ключ, заданный
числом i. Чтобы управлять таким файлом, добавляется таблица
индексов. Таблица упорядочена таким образом, что i-й элемент содержит адрес записи и ее длину. Таблица
индексов может храниться как файл в виде дерева.
При организации прямого доступа
функции доступа выражаются в виде зависимостей от атрибутов записей (значений
полей).
Ключом называют любое поле,
значение которого может служить спецификацией записи.
Ключом может быть одно или
несколько полей.
1. Случай
единственного ключа
Каждая запись содержит
единственный ключ, который ее однозначно идентифицирует.
Доступ осуществляется с помощью
функции ПОИСК(КЛЮЧ, АЛ), которая:
- Либо выдает
логический адрес АЛ записи, если поиск завершился успехом
- Либо сигнализирует,
что такой записи нет
2. Адресация
перемешиванием
В этом методе процедуру ПОИСК
пытаются реализовать непосредственно путем построения функции АЛ = f(КЛЮЧ).
Функция f называется функцией перемешивания, хеширования.
Сложность состоит в обеспечении
условия
f(КЛЮЧ1) <> f(КЛЮЧ2)
Поскольку этого почти никогда не
удается добиться, то используют сочетание прямого и последовательного доступа.
Прямым доступом выбирают группу
записей, а из этой группы последовательным доступом выбирают нужную запись.
3. Индексированные
файлы
Этот метод поиска используют в сочетании с
упорядоченностью множества ключей. Строится таблица соответствия (индекс) между
ключами и логическими адресами.
Индекс
|
КЛЮЧ 1 |
||
|
КЛЮЧ 2 |
||
|
… |
||
|
КЛЮЧ 3 |
||
|
… |
||
|
|
||
|
… |
|
… |
|
Запись 2 |
|
… |
|
Запись 1 |
|
… |
|
Запись 3 |
|
… |
Таблица индексов должна быть
упорядочена. Тогда поиск будет проводиться очень быстро. Возможна организация
этой таблицы в виде дерева.
4. Сложные
ключи
Иногда каждый конкретный ключ не
единственным образом определяет запись. Тогда организуется список записей с
одинаковым значением ключа, а в индексной таблице имеется указатель на первую
запись с таким индексом (на начало списка).
Кроме того, может быть создано
несколько ключей, для поиска записей по разным критериям.
7.3.2. Физическая организация файлов
7.3.2.1. Пример физической
организации файлов системы FAT
Для
начала рассмотрим простейший пример физической организации файлов в системе FAT.
Числа 12, 16, 32 указывают
разрядность, применяемую для идентификации кластера на диске.
FAT12 поддерживает 2**12 = 4096 кластеров. Для FAT12 размер кластера может быть равен от 512 байтов до 8
Кб. Поэтому максимальный размер тома равен 32 Мб.
FAT16 поддерживает 2**16 = 65 536 кластеров. Для FAT16 размер кластера может быть равен от 512 б до 64 Кб.
Поэтому максимальный размер тома равен 4 Гб.

Организация FAT

Пример цепочек размещения файлов в FAT
Последний
кластер файла содержит указатель FFFF. Свободный
кластер содержит указатель 0000.
Запись
в таблице имеет размер 32 байта.
В FAT32 из 32-х битов идентификатора кластера 4 бита
зарезервированы. Максимальный размер кластера FAT32 равен 32 Кб. Поэтому максимальный размер тома равен
8 терабайт.
Т.к. длина файла описывается
32-битным числом, максимальный размер файла равен 4 Гб.
NTFS использует
64-разрядные индексы кластеров. Поэтому может адресовать тома до размера 16
экзабайт (16 миллиардов Гб).
Win2000 ограничивает размеры томов до32-разрядной
индексации кластеров, т.е. до 128 Тб, при размере кластера 64 Кб.
Теперь
перейдем к более общему описанию принципов размещения файлов.
7.3.2.2. Последовательное
размещение
При последовательном размещении
файл занимает совокупность последовательных блоков на носителе.
Такой способ является
единственно возможным на магнитной ленте.
Последовательный доступ очень
быстрый.
Но при большом числе операций по
созданию, уничтожению, расширению и урезанию файлов такой способ неприемлем.
7.3.2.3. Размещение без
использования свойства смежности
Сцепленные блоки
Физические блоки содержат
указатель на следующий блок. Последовательный доступ тоже эффективен, но прямой
– нет.

Таблица размещения
Для повышения эффективности
прямого доступа все указатели помещаются в одну таблицу.
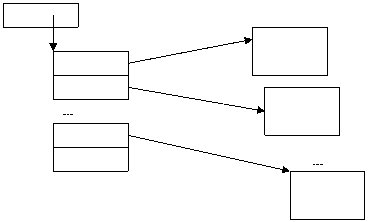
Таблица может содержаться в сцепленных
блоках и может быть многоуровневой.
С видами организации файлов тесно связаны способы
выделения памяти под файлы. Существуют следующие способы выделения памяти под
файлы:
- Непрерывное выделение, при котором сразу же при
создании запрашивается нужный размер, и если его нет, то файл не создается;
- Прерывистое выделение, которое делится на два
вида:
1. Сектор-ориентированное выделение
2. Блочное выделение, при котором группы секторов объединяются в блоки.
Реализации:
1. Цепочки блоков
2. Цепочки индексов блоков
3. Блочно-ориентированное отображение
Прерывистое выделение пространства порождает проблемы
фрагментации файлов. Сборка мусора – один из способов решения этой проблемы.
Интерфейс распределителя внешней
памяти включает два примитива:
ЗАТРЕБОВАТЬ_ЗОНУ(Ч,
А);
ОСВОБОДИТЬ_ЗОНУ(Ч,
А);
Где: Ч – число смежных блоков
А – адрес первого блока
Структура данных, наиболее часто
используемая для описания состояния занятости блока, представляет собой цепочку
битов, в которой i-й бит указывает, занят i-й блок или нет.
7.3.3. Пример
организации файловой системы NTFS
7.3.3.1. Тома и кластеры
Том соответствует логическому
разделу на диске.
На диске может быть один или
несколько томов.
Кроме того, на одном диске могут
совместно существовать тома NTFS и других файловых систем (FAT).
Том состоит из набора файлов и
свободного пространства.
В NTFS данные файловой
системы хранятся как обычные файлы.
Системный администратор может установить квоты
пользователю на допустимый размер его файлов на данном томе.
При превышении лимита ввод-вывод завершается с ошибкой
"диск полный".
Размер кластера (кластерный
множитель) определяется размером тома, но всегда кратен N**2.
NTFS адресует
конкретные места на диске, используя логические номера кластеров (LCN). Кластеры нумеруются от начала до конца.
Для преобразования LCN в
физический адрес NTFS умножает LCN на кластерный множитель и
получает байтовое смещение на диске, воспринимаемое драйвером диска.
7.3.3.2. Главная таблица
файлов
Главная таблица файлов (MFT) занимает центральное место в структуре тома.
MFT реализована
как массив записей о файлах. Размер каждой записи 1 Кб.
Логически MFT содержит по одной строке на
каждый файл тома.
Кроме MFT на каждом томе имеется набор файлов метаданных с
информацией о файловой системе. Имена файлов с метаданными начинаются со знака $.
Обычно каждая запись MFT соответствует одному файлу. Но если у файла много
атрибутов, то может понадобиться более одной записи. Тогда первая запись,
хранящая адреса всех других записей, называется базовой.
При первом обращении к тому NTFS монтирует его.
Т.е. считывает метаданные и формирует внутренние структуры данных, необходимые
для обращений к файловой системе.
В процессе работы NTFS ведет
лог-файл ($LogFile), регистрируя все операции,
влияющие на структуру тома.
Распределение дискового
пространства регистрируется в файле битовых карт ($Bitmap). Каждый бит соответствует кластеру и фиксирует,
свободен кластер или нет.
Файл защиты ($Secure) хранит базу данных дескрипторов защиты, действующих
в пределах тома.
Загрузочный файл ($Boot) хранит код начальной загрузки.
В файле плохих кластеров ($BadClus) регистрируются все сбойные участки тома.
Файл тома ($Volume) содержит имя тома, версию NTFS.
|
0 |
$Mft – MFT |
|
1 |
$MftMirr – зеркальная копия MFT |
|
2 |
$LogFile – лог-файл |
|
3 |
$Volume – файл тома |
|
4 |
$AttrDef – таблица определения атрибутов |
|
5 |
\
- корневой каталог – список файлов и каталогов корневого каталога |
|
6 |
$Bitmap – файл распределения кластеров тома |
|
7 |
$Boot – загрузочный сектор |
|
8 |
$BadClus – файл плохих кластеров |
|
9 |
$Secure – файл параметров защиты |
|
10 |
$UpCase – сопоставление имен с буквами верхнего регистра |
|
11 |
$Extend – каталог расширенных метаданных |
|
12 |
Не
используется |
|
|
… |
|
15 |
Не
используется |
|
16 |
Пользовательские
файлы и каталоги |
Содержимое MFT
7.3.3.3. Структура файловых ссылок
Файл идентифицируется 64-битным
значением, которое называется файловой ссылкой. Файловая ссылка состоит из
номера файла и номера последовательности. Номер файла равен позиции его записи
в MFT минус 1.
Номер последовательности
увеличивается при каждом использовании позиции записи в MFT, что позволяет проверять целостность файловой
системы.
|
63 – 48 |
47 – 0 |
|
Номер
последовательности |
Номер
файла |
Жесткие связи позволяют ссылаться на один и тот же
файл по нескольким путям. Жесткая связь может быть создана функцией CreateHardLink.
NTFS поддерживает
точки соединения. Это механизм, позволяющий "поднимать" каталоги.
Например, если путь "C:\Drivers" –
это ссылка на путь "C:\Winnt\System32\Drivers", то приложение, обращающееся к файлу "C:\Drivers\Ntfs.sys", на
самом деле обращается к файлу "C:\Winnt\System32\Drivers\Ntfs.sys".
7.3.3.4. Имена файлов
NTFS допускает длину каждого имени файла в пути до 255
символов. Имена могут содержать Unicode-символы,
точки и пробелы.
Unicode – 16-битная
кодировка, обеспечивающая уникальное представление любого символа основных
языков мира.
Стандарт POSIX требует выполнения следующих
требований:
- Поддержка имен,
чувствительных к регистру букв
- Поддержка цепочечных
разрешений, когда для доступа к файлу нужны права на доступ к каждому
каталогу на пути к этому файлу
- Поддержка метки
времени изменения файла, отличной от метки времени последней модификации
файла в MSDOS
NTFS поддерживает
все эти требования.
Пространства имен файлов в разных
системах выглядит следующим образом: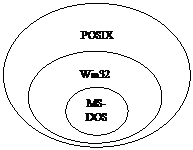
POSIX может создавать
имена с концевыми точками и с концевыми пробелами, например, "TrailingDots…",
"TrailingSpaces ".
При создании файла NTFS система
автоматически создает и имя в стиле MS-DOS. Это имя также можно использовать для работы с
файлом.
Правила генерации MS-DOS имени следующие:
- Удалить все символы,
недопустимые в MS-DOS
- Урезать часть строки
перед точкой до 6 знаков и добавить ~n, где n – номер, начинающийся с 1.
- Урезать строку после
точки до трех знаков
- Преобразовать
символы в верхний регистр
- Увеличить n, если есть файл с таким же именем.
7.3.3.5. Записи о файлах
NTFS рассматривает
файл не просто как хранилище данных, а как совокупность пар атрибутов и их
значений.
Традиционные данные – это значение атрибута
"неименованный атрибут данных".
Другие атрибуты – это имя файла, метка времени,
дополнительные именованные атрибуты.
Пример записи для небольшого файла показан на рисунке.
Каждый атрибут файла хранится
как отдельный поток байтов. Строго говоря, NTFS читает и
записывает не файлы, а потоки атрибутов.
NTFS поддерживает следующие операции над атрибутами:
- Создание
- Удаление
- Чтение
- Запись
Примеры атрибутов перечислены в таблице. На самом деле
атрибуты соответствуют числовым кодам типов.
Каждый атрибут идентифицируется кодом типа, имеет
значение и необязательное имя.
|
$VOLUME_INFORMATION |
|
$STANDARD_INFORMATION |
|
$FILE_NAME |
|
$SECURITY_DESCRIPTOR |
|
$DATA |
7.3.3.6. Резидентные и нерезидентные атрибуты
Если файл невелик, все его
атрибуты и их значения умещаются в одной записи файла. Когда значение атрибута
хранится непосредственно в записи MFT,
атрибут называют резидентным.
Некоторые атрибуты всегда
резидентные, например, имя файла.

Резидентный атрибут и его значение
Если значение атрибута хранится
в MFT, обращение к нему очень быстрое.
Если атрибут не помещается в MFT, то для него выделяются отдельные кластеры за
пределами MFT. Эта область называется группой или экстентом.
Атрибуты, значения которых
хранятся в группах, называются нерезидентными. Нерезидентными могут быть те
атрибуты, чей размер может меняться.
NTFS отслеживает
выделяемые группы путем сопоставления VCN (virtual cluster number) и LCN (logical
cluster number)/
Иллюстрация хранения данных в
группе представлена на рисунке.
|
Резидентная часть атрибута "Данные" |
||
|
Начальный VCN |
Начальный LCN |
Число кластеров |
|
|
1355 |
4 |
|
|
1588 |
4 |

|
VCN 0 |
VCN 1 |
VCN 2 |
VCN 3 |
|
|
Данные |
Данные |
Данные |
|
LCN 1355 |
LCN 1356 |
LCN 1357 |
LCN 1358 |
![]()
|
VCN
4 |
VCN
5 |
VCN
6 |
VCN
7 |
|
Данные |
Данные |
Данные |
Данные |
|
LCN
1588 |
LCN
1589 |
LCN
1590 |
LCN
1591 |
![]()
7.3.3.7. Индексация
NTFS позволяет
индексировать атрибуты файлов. Это дает возможность вести эффективный поиск
файлов по заданным критериям.
В NTFS каталог – это
индекс имен файлов, т.е. совокупность имен, организованная т.о., чтобы
обеспечить быстрый доступ.
В резидентной части хранится
список всех подкаталогов и файлов данного каталога. Подкаталог имеет ссылку на
буфер, в котором описаны все файлы и подкаталоги данного подкаталога.
Описание файла – это ссылка на запись в MFT, описывающую данный файл, информация о размере файла
и метка времени.
Т.о., информация о размере и
метка времени для файла хранится дважды и ее дважды надо обновлять при
изменениях, но потери от этого компенсируются быстротой поиска данных атрибутов
файла.
Список организован в виде b-дерева, что позволяет проводить быстрые процедуры
поиска.
Буфер размером 4 Кб может
содержать 20 – 30 записей для имен файлов.
7.3.3.8. Сжатие данных и разреженные файлы
7.3.3.8.1. Общая характеристика сжатия
данных и разреженных файлов
NTFS не
предпринимает специальных мер по поддержанию непрерывного размещения файлов на
диске.
В Win2000 есть API дефрагментации на основе
управляющих кодов файловой системы.
Встроенная утилита существует,
хотя у нее есть ограничения – невозможность запуска из командной строки и
автоматического запуска по расписанию.
NTFS поддерживает
сжатие по отдельным файлам, по каталогам и по томам.
NTFS поддерживает
прозрачное сжатие файлоав. Сжатие производится функцией DeviceIoControl, которой передается управляющий код FSCTL_SET_COMPRESSION.
У сжатого файла установлен атрибут FILE_ATTRIBUTE_COMPRESSED.
Разреженные файлы – это второй тип сжатия. Для частей
разреженного файла, которые определены приложением как пустые, не выделяется
место на диске.
При чтении такой области NTFS просто
возвращает нули в буфер приложения.
7.3.3.8.2. Сжатие разреженных данных
Разреженными называются данные,
в которых лишь малая часть отлична от нулевых значений.
Для обозначения кластеров файла
используются VCN. Каждый VCN соответствует LCN на диске.
Например:
|
VCN |
0 |
1 |
2 |
3 |
|
4 |
5 |
6 |
7 |
|
8 |
9 |
10 |
11 |
|
|
Data |
Data |
Data |
Data |
Data |
Data |
Data |
Data |
Data |
Data |
Data |
Data |
||
|
LCN |
1355 |
1356 |
1357 |
1358 |
1588 |
1589 |
1590 |
1591 |
2033 |
2034 |
2035 |
2036 |
Запись MFT для этого файла
выглядит следующим образом:
|
Начальный
VCN |
Начальный
LCN |
Число
кластеров |
|
0 |
1355 |
4 |
|
4 |
1588 |
4 |
|
8 |
2033 |
4 |
Предположим, что в кластерах с VCN 2, 3, 6, 7 находятся одни нули. Тогда для них не
выделяется дисковое пространство, и запись в таблице MFT будет выглядеть
следующим образом:
|
Начальный
VCN |
Начальный
LCN |
Число
кластеров |
|
0 |
1355 |
2 |
|
4 |
1588 |
2 |
|
8 |
2033 |
4 |
Видно, что интервалам 0 – 4 и 4
– 8 не соответствует число кластеров 2 (и 2). Это является признаком, что сжат
разреженный файл.
Если программа
"натыкается" на VCN, которому не
выделен LCN, она возвращает нули в программу без обращения к диску.
7.3.3.8.3. Сжатие неразреженных данных
NTFS разбивает файл
на группы по 16 кластеров. Каждую группу пытается сжать каким-нибудь алгоритмом
сжатия.
Например, группы сжатого файла
могут выглядеть следующим образом:
|
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
|
Сжатые данные |
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
19 |
20 |
21 |
22 |
|
|
|
|
|
|
|
|
|
|
|
|
|
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
24 |
25 |
26 |
27 |
28 |
29 |
30 |
31 |
|
Сжатые данные |
|
|
|
|
|
|
|
|
|||||||
|
23 |
24 |
25 |
26 |
27 |
28 |
29 |
30 |
|
|
|
|
|
|
|
|
|
32 |
33 |
34 |
35 |
36 |
37 |
38 |
39 |
40 |
41 |
42 |
43 |
44 |
45 |
46 |
47 |
|
Несжатые данные (не сжались) |
|||||||||||||||
|
97 |
98 |
99 |
100 |
101 |
102 |
103 |
104 |
105 |
106 |
107 |
108 |
109 |
110 |
111 |
112 |
|
48 |
49 |
50 |
51 |
52 |
53 |
54 |
55 |
56 |
57 |
58 |
59 |
60 |
61 |
62 |
63 |
|
Сжатые данные |
|
|
|
|
|
|
|||||||||
|
113 |
114 |
115 |
116 |
117 |
118 |
119 |
120 |
121 |
122 |
|
|
|
|
|
|
Запись в MFT для
такого файла будет выглядеть следующим образом:
|
Начальный
VCN |
Начальный
LCN |
Число
кластеров |
|
0 |
19 |
4 |
|
16 |
23 |
8 |
|
32 |
97 |
16 |
|
48 |
113 |
10 |
Из информации о длине группы
кластеров в записи видно, какие группы сжаты (1, 2, 4), а какие – нет (3).
7.3.3.9. Файл журнала изменений
Многим программам необходимо отслеживать изменения в
файлах и каталогах.
- Один из путей (самый
трудоемкий) – сравнение содержимого, что плохо влияет на
производительность системы.
- Другой путь (не
самый информативный) – зарегистрироваться на получение уведомлений об
изменениях. Правда, функции этой части API сообщают
лишь о факте изменения, а не о конкретных изменениях.
- Третий путь (попытка
устранить недостатки 1-го и 2-го путей) – настройка журнала регистрации
изменений на фиксацию изменений в файлах заданного каталога.
Когда приложение активизирует
регистрацию изменений, система создает такой файл. Записи файла включают
следующую основную информацию:
- Время изменения
- Тип изменения
(удаление, переименование, увеличение размера и т.д.)
- Атрибуты файла или
каталога
- Имя файла или
каталога
7.4. Дескриптор файла и реализация основных функций доступа к файлу
7.4.1. Состав дескриптора файла
Структура дескриптора определяется
типом файловой системы. Типовой дескриптор содержит следующие данные:
1)
идентификатор
файла;
2)
сведения о
размещении файла
3)
информация для управления
доступом.
- Идентификатор файла,
состоящий из символического имени и внутреннего идентификатора
Внутренний
идентификатор – ключ доступа, например, номер в таблице имен
- Физический адрес,
указывающий расположение файла на диске
- Тип устройства
хранения
Два
варианта – либо данные хранятся в самом дескрипторе, либо в дескрипторе
хранятся ссылки на таблицы, в которых описано, где находятся данные.
- Информация
управления доступом – кто и как может пользоваться файлом
- История и результаты использования
Дата/время создания
Дата/время последней модификации
Дата удаления
Счетчик обращений - Статус (временный,
постоянный)
- Тип
- Кодировка
- Физическая
организация
Кроме перечисленных в дескрипторе данных, для анализа
файла используют следующие характеристики файла:
- Изменяемость –
частота добавлений, удалений
- Активность – доля
записей, обрабатываемых за один проход
- Размер – количество
информации в файле
Другим способом структуризации информации,
содержащейся в дескрипторе, является следующий способ:
Дескриптор
содержит нформацию о физической реализации файла:
К данной информации относится в первую очередь:
- Указатель на таблицу
размещения
- Размер таблицы
размещения
- Размер файла
Дескриптор
содержит нформацию об использовании файла в текущий момент:
- Информация состояния
(открыт, закрыт, число пользователей и т.д.)
- Информация о
содержимом (тип – текст, бинарный, каталог, перемещаемый и т.д.)
- Информация о
логической структуре (записи фиксированного/переменного размера)
- Информация о прошлом
использовании (число открытий, доступов, средний интервал обращений)
7.4.2. Реализация основных функций доступа
Операция создания
Предоставляемыми
параметрами являются:
- Имя файла
- Тип (не всегда)
- Размер (не всегда)
- Начальное состояние
(не всегда)
Алгоритм:
- Создать дескриптор
- Создать вход для
этого файла в текущем каталоге
- Выделить память для
файла (даже если в начале размер нулевой, есть заголовок, который занимает
размер)
- Инициализировать
дескриптор сведениями о локализации, размере, типе, защите
- Если дескриптор не
содержится в каталоге, то вход оснастить ссылкой на дескриптор
Исключительные ситуации
1. Неправильное имя файла
2. Нет места во внешней памяти
Операция уничтожения
Передаваемым
параметром является имя файла.
Алгоритм
- Освободить память,
выделенную для файла
- Освободить память,
выделенную под дескриптор
- Уничтожить внешнее
имя файла в каталоге (сложная операция, если файл имеет несколько имен). В
последнем случае используется счетчик ссылок. Когда остается последнее
имя, файл реально уничтожается.
Операция открытия
Параметрами
операции открытия являются:
- Имя файла
- Способ доступа
(чтение, запись, выполнение)
- Процедуры доступа
(прямой, последовательный)
- Буфер доступа
Алгоритм
- Локализация файла
(установка носителя, если не установлен)
- Контроль прав
пользователя на открытие в данном режиме
- Создание локального
дескриптора
- Выделение
необходимой памяти для буферов ввода-вывода
Исключительные ситуации
- Условия ткрытия
несовместимы с правами пользователя
- Невозможность
открытия из-за разделяемого доступа.
- Отсутствие места в
памяти для дескриптора и буферов.
Операция закрытия
Передаваемым
параметром является имя файла.
Алгоритм
- Фиксируются
модификации, выполненные во время работы с файлом
- Уничтожается
локальный дескриптор
- Память, занятая под
буфера ввода-вывода освобождается
7.4.2.5. Операции доступа к информации
Параметры
примитивов позволяют специфицировать следующие факторы:
- Используемый метод
доступа (последовательный, прямой);
- Синхронизацию
(синхронный, асинхронный);
- Буферы и их размеры;
- Результаты
выполнения операции.
Доступ
(чтение или запись) к записи файла состоит из двух этапов:
- Определение
физического адреса по логическому
- Физическая передача
данных (см. раздел 4).
7.5. Защита файлов
Понятие "защита" охватывает совокупность
методов, которые определяют правила использования информации и гарантируют их
выполнение. Они основаны на понятии прав доступа и механизмах, гарантирующих их
соответствие операциям над файлом.
Для защиты файлов используются списки доступа, которые
для каждого пользователя содержат его права на файл, т.е. совокупность
разрешенных операций.
На практике этот списки
сокращают, создавая права "по умолчанию" и права групп пользователей.
Информация управления доступом
определяет тип защиты, назначенный файлу.
В большинстве систем данные
управления доступом представлены как списки полномочий в виде пар <C, A>, где С –
это пользователь, а А – атрибут доступа, показывающий как файл может быть
использован.
Часто пары <С, А> обобщают
в матрицы доступа примерно следующего вида:
|
файл пользователь |
1 |
2 |
3 |
4 |
|
1 |
1 |
1 |
0 |
0 |
|
2 |
0 |
0 |
0 |
1 |
|
3 |
1 |
1 |
1 |
0 |
|
4 |
0 |
0 |
0 |
1 |
Когда файлов и пользователей
становится очень много, управление с помощью матрицы становится неприемлемым.
Тогда пользователей делят на
классы:
- Владелец
- Специфицированный
пользователь
- Группа или проект
- Общий
Вот, например, описание способа защиты, имеющего место
в файловой системе NTFS.
Открытый файл реализуется в виде объекта
"файл" с дескриптором защиты, хранящимся на диске как часть файла.
Прежде чем процесс сможет выполнить какое-либо
действие с объектом "файл", система защиты проверяет, есть ли у
процесса соответствующие полномочия.
Наличие дескриптора защиты в сочетании с регистрацией
пользователей гарантирует, что ни один процесс не получит доступа к файлу без
разрешения администратора или владельца.
Другой стороной защиты является
возможность шифрования данных.
NTFS поддерживает
механизм Encrypting File System (EFS), с помощью которого пользователи могут шифровать
данные. EFS полностью
прозрачен. Файлы доступны только из приложений, работающих под учетной записью
пользователя, имеющего на это право.
EFS – Encrypting File System – средства поддержки шифрования.
При первом шифровании файла EFS назначает
учетной записи пользователя криптографическую пару – закрытый и открытый ключи.
При шифровании генерируется
случайное число, называемое шифровальным числом файла (FEK – file encryption key).
С помощью этого ключа шифруется
файл по алгоритму DES (data encryption standard),и ключ в зашифрованном
виде хранится вместе с файлом.
Но ключ шифруется по алгоритму RSA на основе открытого ключа.
Пользователи не могут
расшифровать данные без расшифровки ключа, а ключ не могут расшифровать без
закрытого ключа пользователя – владельца файла.
EFS реализована в
виде драйвера, работающего в режиме ядра и тесно связанного с драйвером
файловой системы NTFS.
7.6. Безопасность файлов
7.6.1. Общие принципы обеспечения безопасности
Понятие "безопасностью" охватывает
совокупность методов, которые обеспечивают реализацию всех операций над файлами
в соответствии с их спецификацией, даже в случае сбоев. Это, по сути,
устойчивость системы к сбоям, она основана на использовании дополнительной
информации.
Примерами последствий сбоев могут быть следующие
явления:
- Разрушение
справочных таблиц
- Появление
указателей, не связанных с объектами
- Запись неверных
данных
Безопасность обеспечивается двумя направлениями.
- Внутренней
избыточностью
- Периодическим
сохранением
Принцип внутренней избыточности
основан на том, что любая информация может быть получена по крайней мере двумя
разными способами. Широко используются следующие способы:
- При сцеплении блоков
используется двойное сцепление
- В каждый блок
включается указатель на дескриптор
- Часть дескриптора
дублируется (например, в первом и последнем блоке файла)
Примерами способов проверки несогласованности данных
за счет избыточностиьявляются следующие:
- Проверка адресов на
допустимые диапазоны;
- Проверка дублируемой
информации на совпадение;
- Применение
контрольных сумм.
Самым общим методом сохранения
данных является периодическое создание резервных копий файлов. Через регулярные
интервалы времени сохраняется информация, содержащаяся в СУФ.
А самой общей основой процедур восстановления являются
серии восстановлений файлов из резервных копий в попытке воссоздать систему в
таком состоянии, в каком она была непосредственно перед сбоем.
Процедуры резервирования
выполняют дампы частей системы.
Практикуются выборочные и
инкрементные дампы, получаемые через небольшие интервалы времени, и полные
дампы в контрольных точках, более редких.
Инкрементные дампы копируют только
модифицированные после последнего сеанса сохранения данные.
Т.е. общий принцип такой – чем более полное сохранение
делается, тем более редко оно делается.
Периодическое сохранение имеет
несколько недостатков:
- Система может дать
сбой при самой операции сохранения. Результаты операций, выполняющихся в
это время, будут потеряны.
- Система может быть
огромной
- Восстановление может
потребовать значительного времени.
Другой метод состоит в том, чтобы записывать все
транзакции файла, копируя их на другой диск. Это дорого, но надежно.
Рассмотрим
в качестве примера систему восстановления при отказах, реализованную в NTFS.
7.6.2. Поддержка восстановления NTFS
7.6.2.1. Общая характеристика средств восстановления
Восстанавливаемость основана на
обработке транзакций.
Восстанавливаемость
подразумевает сохраняемость структуры системы при авариях. Но не обеспечивает
сохраняемость данных пользователя.
Это компромисс между полной
отказоустойчивостью и производительностью.
NTFS обеспечивает восстановление файловой системы на
основе концепции атомарной транзакции.
Атомарная транзакция – это метод обработки изменений в базе данных, при котором
сбои не нарушают целостности базы данных.
Суть атомарных транзакций заключается в том, что
некоторые операции над базой, называемые транзакциями, выполняются по принципу
"все или ничего".
Транзакцией будем называть операцию ввода-вывода,
изменяющую данные файловой системы или структуру каталогов тома.
Отдельные изменения на диске, составляющие транзакцию,
выполняются атомарно: в ходе транзакции на диск должны быть внесены все
требуемые изменения.
Если
транзакция прервана аварией, то часть изменений, уже внесенных к этому моменту,
нужно отменить. Такая отмена называется откатом.
После отката база данных возвращается в исходное состояние, в котором она была
до начала транзакции.
7.6.2.2. Типы восстановления файловой системы
Исторически существовали два
типа файловых систем с точки зрения восстанавливаемости:
Системы
с точной записью (VAX/VMS)
Системы
с отложенной записью (HPFS (OS/2), UNIX)
Дополнительно
существуют системы со сквозной записью (FAT MS-DOS, обновления записываются на диск немедленно)
NTFS отличается от
этих систем
Файловые системы с точной записью
В случае аварии операции
ввода-вывода немедленно прерываются. В зависимости от того, на сколько
продвинулся ввод-вывод, прерывание может нарушить целостность системы.
Под целостностью понимается
повреждение файловой системы. Например, имя файла есть в списке каталога, а сам
файл недоступен.
В файловой системе с точной
записью все операции выполняются последовательно. Например, при выделении
дискового пространства сначала устанавливаются биты занятости в битовой карте,
а потом выделяется пространство.
Если после установления битов произойдет сбой питания,
то система потеряет доступ к этой части диска.
Преимущество такой системы состоит в том, что после
сбоев том все равно можно использовать, хотя бы и с некоторыми ограничениями.
Файловые системы с отложенной записью
В системах с отложенной записью
все изменения записываются в кэш, а содержимое последнего сбрасывается на диск
оптимизированным способом в фоновом режиме.
Производительность этого метода
выше, поскольку уменьшается число обращений к диску.
Недостаток состоит в том, что
бывают моменты, когда том находится в несогласованном состоянии из-за множества
отложенных запросов. В случае аварии эту несогласованность нельзя исправить.
7.6.2.3. Восстанавливаемые файловые
системы
7.6.2.3.1. Общая характеристика
восстанавливаемой файловой системы
Восстанавливаемая файловая
система превосходит по надежности файловые системы с точной записью и достигает
уровня производительности систем с отложенной записью.
Система ведет журнал изменений.
В случае аварии система выполняет процедуру восстановления на основе информации
этого журнала.
Восстанавливаемость гарантирует,
что структура тома не будет разрушена, т.е. все файлы останутся доступными.
Сброс КЭШа и сквозная запись
повышают надежность и пользовательских данных.
7.6.2.3.2. Протоколирование
Восстанавливаемость обеспечивается опережающим
протоколированием (write-ahead logging). Прежде
чем выполнить какую-либо транзакцию, изменяющую структуру данных файловой
системы, NTFS регистрирует ее в файле журнала.
7.6.2.3.3. Сервис файла журнала
Сервис файла журнала – это набор
процедур режима ядра, локализованных в драйвере NTFS, который она использует для доступа к файлу журнала.
Файл журнала содержит две
области:
- Область перезапуска
(две копии)
- Область протоколирования
|
Область
перезапуска, копия 1 |
Область
перезапуска, копия 2 |
Область
протоколирования, записи журнала |
Область перезапуска хранит
позицию в области протоколирования, с которой начнется чтение при
восстановлении после сбоя.
Записи можно читать в прямом
направлении, чтобы повторить все транзакции, которые запротоколированы, но не
записаны на диск.
Записи можно читать в обратном
направлении, чтобы откатить транзакции.
Этапы выполнения транзакции:
- Транзакция
регистрируется в журнале, но в КЭШе
- Транзакция
выполняется в КЭШе
- Сбрасывается на диск
кэш журнала
- Сбрасывается на диск
кэш транзакции
7.6.2.3.4. Типы записей журнала
Основные типы записей следующие:
- Записи модификации
- Записи контрольной
точки
Записи модификации
Запись модификации содержит два
вида информации:
- информация для
повтора, описывающая как вновь применить подоперацию полностью
запротоколированной транзакции, если сбой произошел до того, как
транзакция была переписана из КЭШа на диск
- информация для
отмены, описывающая, как обратить изменения, вызванные одной подоперацией
транзакции, которая в момент сбоя была запротоколирована лишь частично.
|
Область
перезапуска |
Область
протоколирования, записи журнала |
||||
|
|
… |
1. повтор: создать запись о файле в MFT 2. отмена: удалить запись о файле из MFT |
1. повтор: добавить имя файла в индекс 2. отмена: удалить имя файла из индекса |
1. повтор: установить бит в битовой карте 2. отмена: сбросить бит в битовой карте |
… |
Пример записи модификации
После протоколирования
транзакции NTFS выполняет в КЭШе подоперации этой транзакции. Закончив
обновление КЭШа, NTFS помещает в журнал еще одну запись, которая помечает
всю транзакцию как завершенную (committed).
При восстановлении NTFS повторяет
все зафиксированные транзакции, т.к. не знает, были ли изменения тома
переписаны из КЭШа на диск.
Все подоперации незавершенных
транзакций NTFS откатывает.
Информация для повтора и отмены
может быть выражена физически или логически. Физическое описание – это
множества байтов на диске, которые надо изменить, переместить и т.д. Логическое
описание – это информация в терминах "удалить файл". NTFS использует
физическое описание, а приложениям восстановления легче использовать логическое
описание.
Записи модификации генерируются
для следующих транзакций:
- Создание файла
- Удаление файла
- Расширение файла
- Урезание файла
- Установка файловой
информации
- Переименование файла
- Изменение прав
доступа к файлу
Требования к точности информации восстановления очень
высоки.
Записи контрольной точки
Кроме записей модификации NTFS периодически помещает в лог-файл (файл журнала)
записи контрольной точки.
Запись контрольных точек
помогает определить, какая обработка нужна для восстановления, если сбой
произошел сразу после добавления этой записи в журнал.
Благодаря этим записям NTFS знает,
как далеко назад ей нужно пройти по журналу, чтобы начать восстановление.
Добавив новую запись контрольной
точки, NTFS записывает ее номер в область перезапуска, поэтому,
начиная восстановление после сбоя, она быстро находит самую последнюю запись
контрольной точки.
|
Область перезапуска |
Область протоколирования |
|||||
|
|
Записи лог-файла |
|||||
|
… |
LSN 2058 |
LSN 2059 |
LSN 2060 |
LSN
|
… |
|
![]()
LSN – логический номер последовательности.
7.6.2.3.5. Восстановление
NTFS выполняет
восстановление при первом обращении к нему какой-либо программы после загрузки.
При восстановлении используются
две поддерживаемые таблицы:
- Таблица транзакций –
предназначена для отслеживания начатых, но еще не зафиксированных
транзакций
- Таблица измененных
страниц – содержит список страниц КЭШа, содержащих изменения структуры
файловой системы, еще не записанные на диск.
Записи контрольной точки
добавляются каждые 5 сек. Перед этим моментом содержимое таблиц сохраняется.
В начале процесса восстановления NTFS ищет
в лог-файле, самую последнюю запись контрольной точки и по ней восстанавливает
содержимое таблиц.
При восстановлении тома NTFS выполняет три
прохода по лог-файлу:
- анализ
- повтор транзакций
- отмена транзакций
Анализ
При проходе анализа NTFS просматривает
журнал в прямом направлении, чтобы найти записи модификации и обновить
скопированные таблицы транзакций и измененных страниц.
|
… |
Таблица
измененных страниц |
Запись
модификации |
Таблица
транзакций |
Запись
контрольной точки |
Запись
модификации |
Запись
модификации |
… |
![]()
![]()
Начало операции контрольной
точки Конец
операции контрольной точки
Записи модификации, появившиеся
после начала операции контрольной точки, обычно относятся к изменениям таблиц
транзакций и измененных страниц.
По этим записям таблицы
актуализируются.
После этого NTFS просматривает
таблицы и ищет самые старые записи, которые регистрируют операции, не
выполненные над диском.
Повтор транзакций
На проходе повтора сканируется
журнал транзакций в прямом направлении, начиная с LSN самой старой
записи, которая была обнаружена на проходе анализа.
Ищутся записи модификации,
которые были запротоколированы до сбоя, но не сброшены из КЭШа на диск. NTFS повторяет
эти обновления в КЭШе, а затем они сбрасываются на диск.
|
… |
Запись
модификации |
… |
Таблица
измененных страниц |
Запись
модификации |
Таблица
транзакций |
Запись
контрольной точки |
Запись
модификации |
… |
![]()
![]()
Начало
операции контрольной точки
Самая старая запись журнала, не
сброшенная на диск
Проход отмены
Завершив проход повтора, NTFS начинает
проход отмены, откатывая транзакции, не зафиксированные к моменту сбоя.
Записи модификации, относящиеся
к одной транзакции, связываются указателями, поскольку не обязательно
располагаются одна за другой.
В таблице транзакций для каждой
незавершенной транзакции хранится LSN записи модификации, помещенной в
журнал последней.
Например, это запись 4049. Тогда
NTFS находит
эту запись, делает откат. Затем перемешается по обратному указателю, находит
запись 4048 и снова делает откат. Также делает и с записью 4046.
|
... |
LSN
4044 |
LSN
4045 |
LSN 4046 |
LSN
4047 |
LSN 4048 |
LSN 4049 |
… |
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Жирным
шрифтом обозначена зафиксированная транзакция.
Обычным
шрифтом обозначена незафиксированная транзакция.
Когда восстановление завершено, NTFS помещает
пустую область перезапуска в Лого-файл, указывающую на то, что диск находится в
согласованном состоянии.
Само восстановление тоже
регистрируется. Кроме того может произойти сбой при восстановлении.
Журнал очень информативен,
поэтому используется не только при восстановлении после сбоев, но и для отката
операций, вызванных ошибками пользователя.
Например, начали создавать файл
(записи в MFT), а потом выяснилось, что диск
полон. Тогда начальные этапы создания файла будут откатаны.
7.6.2.4. Восстановление плохих
кластеров в NTFS
Если данные не удается считать
из-за повреждения сектора, то ФС выделяет новый кластер, заменяющий тот, на
котором находится плохой сектор, и копирует данные в этот кластер.
Плохой кластер помечается как аварийный и больше не
используется.
Когда NTFS получает ошибку, связанную с плохим сектором, она
присоединяет содержащий его кластер к своему файлу плохих кластеров.
Это предотвращает повторное
использование плохого кластера.
Затем выделяется новый кластер и
изменяется сопоставление VCN-LCN для
файла.
Если плохой сектор находится на
томе с избыточностью данных, то при замещении кластера данные
восстанавливаются. Это делает диспетчер томов.
Если данные восстановить нельзя,
то выдается сообщение.
Восстановлением данных
занимается диспетчер томов, а NTFS занимается переназначением кластеров. Поэтому
восстановление данных возможно и в FAT.
Раздел 8. Управление информацией в операционных системах
8.1. Общая характеристика
связывания объектов
Если обратиться к
иерархической структуре операционной среды, то уровень, о котором пойдет речь
теперь - это уровень "каталогов".
Уровень каталогов - это
уровень, на котором происходит связывание имен объектов операционной среды с
самими объектами.
Объекты, которые составляют
любую программную среду, представляются своими внешними именами. Мы обращаемся
к объектам по их внешним именам.
Внешние имена объектов - это, как правило,
цепочки символов. Например, идентификаторы переменных в программах.
Сами же объекты реализуются
в среде в виде набора данных в соответствие с их типами и, начиная с некоторых
адресов в памяти. Поэтому сама среда пользуется для доступа к объекту его
внутренним именем, которое чаще всего является начальным адресом расположения
объекта в памяти.
Таким образом, должна
существовать, и существует технология, по которой через внешнее имя объекта
осуществляется доступ к самому объекту. Т.е. производится связывание внешнего и
внутреннего имен объекта.
Эта технология называется
технологией связывания и составляет суть управления информацией в операционной
среде.
Итак, есть внешнее имя объекта, а есть его
внутреннее имя - адрес. Отношение, определенное на множестве имен и адресов,
называется цепью доступа.
Приведенный рисунок
иллюстрирует простую однозвенную цепь доступа.
Простая цепь доступа может быть и многозвенной, если
в системе используются и промежуточные имена.

Примером такой многозвенной
цепь доступа может служить цепь доступа к файлу - есть внешнее имя файла, затем
есть файловая переменная, затем - внутреннее имя файла (обычно некоторое
число), через которое осуществляется доступ к самому файлу.
Помимо простой цепи доступа может
существовать сложная цепь доступа - цепь доступа через дескриптор:

Доступ через дескриптор
сложнее, чем простой доступ, но обладает более богатыми возможностями.
Дескриптор - это сложная
структура данных, описывающая объект. Содержание дескриптора зависит от
характера объекта.
Примеры дескрипторов из различных разделов ОС нам известны:
1) дескрипторы процессов;
2) дескрипторы сегментов;
3) дескрипторы файлов.
Использование дескрипторов обладает следующими достоинствами:
1) Дескриптор, как средство
доступа к объекту, позволяет легко контролировать и регламентировать доступ к
объекту;
2) Дескриптор, как средство
косвенного доступа к объекту, позволяет динамически менять путь доступа к
объекту или перемещать объект в памяти;
3) Дескриптор - это, как
правило, программная структура фиксированного размера, что облегчает управление
ею, например, передачу в процедуру в качестве параметра.
Построение цепи доступа
называется связыванием.
Связывание может
производиться на различных этапах жизненного цикла объекта:
1) На этапе написания
программы (в кодах). Каждый объект сразу представляется своим абсолютным
адресом. Эффективность выполнения такой программы очень высока, но проблемы модификации
и переносимости решаются очень тяжело. Такие программы можно писать для не
очень сложных контроллеров встроенных систем.
2) На этапе трансляции
программы. Здесь появляется ассемблер - символическая запись команд и данных.
Во время трансляции имена переменных - идентификаторы заменяются абсолютными
адресами. Программы получаются неперемещаемыми.
3) На этапе загрузки
программы. В этом случае трансляция выполняется в относительные адреса, а
процесс загрузки заключается в преобразовании относительных адресов в
абсолютные. Программы получаются перемещаемыми.
Если программа состоит из
ряда модулей, а это имеет место практически всегда (даже если программист пишет
программу, состоящую из одного модуля, он все равно использует библиотечные
модули), загрузку предваряет редактирование связей.
Редактирование связей - это
установление связей между объектами, находящимися в различных оттранслированных
модулях, и создание перемещаемого загрузочного модуля. Этот загрузочный файл
содержит все требуемые библиотечные модули.
4) На этапе выполнения
программы. В этом случае связывание называется динамическим.
Примерами динамического
связывания являются виртуальные методы Объектно-Ориентированного
Программирования, а также динамические библиотеки.
Динамическое связывание делится на два вида:
1) Динамическое связывание
на этапе загрузки, когда требуемые библиотечные модули подгружаются к программе
на этапе ее загрузки. Такой способ связывания называется неявным.
2) Динамическое связывание
на этапе выполнения, когда библиотечные модули подгружаются по мере надобности
явными вызовами из программы. Такой способ связывания называется явным.
Далее мы более подробно
рассмотрим второй, третий и четвертый методы связывания.
8.2. Загрузка абсолютной
программы
Этот вид загрузки является
наиболее простым из рассматриваемых видов, и мы его будем рассматривать как
введение в более сложные алгоритмы загрузки.
Здесь мы рассмотрим, что же
собой представляет объектный код, являющийся результатом трансляции.
Реальная структура объектного
кода может быть различной в зависимости от системы. Мы будем рассматривать
некую абстрактную систему, тем не менее, считая, что в реальной системе
обязательно должна присутствовать та же самая информация, но может быть в
несколько иной форме.
Будем считать, что объектная
программа представляет собой совокупность записей трех типов:
1) запись-заголовок;
2) запись-тело;
3) запись-окончание.
Запись-заголовок имеет следующий вид:
Н.Имя_программы.Размер_программы
Запись-тело имеет следующий вид:
T.Начальный_адрес_записи.Размер_записи.Коды_команд_и_данных
Запись-окончание имеет следующий вид:
Е.Адрес_первой_исполняемой_команды
Пример. Напишем
программу PROG, имеющую следующий код:
push ds 1E
mov ax, 0 B8
00 00
push
ax 50
ret CB
Считая, что программа должна
располагаться с нулевого адреса, в соответствие с нашим определением объектная
программа будет иметь следующий вид:
H PROG 6
T 0000 1 1E
T 0001 3
B80000 ; B8 00 00
T 0004 1 50
T 0005 1 CB
E 0000
Или H PROG 6
T 0000 6 1EB8000050CB ; 1E B8 00 00 50 CB
E 0000
Алгоритм работы загрузчика
для такой программы достаточно прост:
1) Просматриваем
запись-заголовок и сравниваем размер программы с имеющейся свободной памятью.
Если памяти не хватает, то не грузим программу, если памяти хватает, то
переходим к пункту 2.
2) Последовательно считываем
записи-тела и располагаем коды команд и данных из этих записей в памяти по
указанным адресам. Делаем это, пока не дойдем до записи-окончания.
3) Дойдя до записи-окончания,
делаем переход на адрес, указанный в этой записи, т.е. к первой выполняемой
инструкции программы.
8.3. Загрузка перемещаемой
программы
В предыдущем примере
говорилось о случае, когда заранее известно место в памяти, куда будет
загружаться программа. Это случай нетипичный. Наиболее типичным является случай,
когда начальный адрес программы не известен до момента загрузки.
Рассмотрим простейший пример.
Предположим, что наша
программа может быть загружена с начального адреса 0000, по адресу 0000 у нас
находятся данные, и мы хотим загрузить их в регистр ах. Мы напишем инструкцию,
подобную следующей:
mov
ax, [0000]

Запись-тело для такой
инструкции будет выглядеть следующим образом:
Т 0007 4 8A260000 ; 8А 26 0000 (0007 - адрес инструкции)
Теперь предположим, что мы хотим загрузить
нашу программу не с адреса 0000, а с адреса 2000. Смотрим правую карту памяти.
Помимо того, что адресная
часть записей объектного кода (второй столбец записей с признаками Т и Е)
должна измениться с 000Х на 200Х, должна измениться и информация внутри записей,
а именно, там, где в записи-теле есть адрес 0000, должен стоять адрес 2000.
Т.е. записи должны подвергнуться модификации, для того чтобы программа стала
перемещаемой.
Поэтому в объектном коде
перемещаемой программы существуют записи еще и другого, кроме Н, Т и Е, типа.
Эти записи называются записями-модификаторами. Структура их, в общем виде,
имеет следующий вид:
М.Адрес_модифицируемого_поля.Значение_модификации
В нашем конкретном примере
запись-модификатор, относящийся к инструкции mov ax, [0000], будет иметь вид:
М 0009 2000
Для каждого перемещаемого
данного должна существовать запись-модификатор.
Есть и другие способы
хранения данных для модификации, но в информационном плане они не отличаются от
приведенного.
Например.
Добавление в запись-тело признака модификации.
Запись: Т 0007 4 8А260000 может быть изменена
следующим образом:
Т 0007 2 8А26
Т
0009 2 0000
После длин поля добавляется
признак модификации 1 - перемещаемый код, 0 - неперемещаемый код.
Т 0007 2 0 8А26
Т
0009 2 1 0000
Загрузчик анализирует это
поле записи в процессе загрузки и добавляет при необходимости к данным
начальный адрес.
А в общем плане перемещение
- это (пока) довольно несложная процедура, заключающаяся в прибавлении
константы - начального адреса загрузки к некоторым полям данных записей
объектного кода программы.
Отметим, что сегментация -
это один из путей решения задачи перемещения. Внутри программы почти ничего не
надо перемещать, достаточно настроить сегментные регистры на некоторые
начальные адреса и перемещение будет происходить автоматически.
Алгоритм перемещающего
загрузчика похож на алгоритм абсолютного загрузчика, приведенный выше, но в
пункт 2 необходимо добавить анализ признака модификации кода перед загрузкой.
8.4. Редактирование связей
Под редактированием связей
здесь понимается построение загружаемой программы из нескольких объектных
модулей в отличие от предыдущего случая построения загружаемой программы из
одного объектного модуля.
Для того чтобы понять, о чем
здесь будет идти речь, вернемся сначала к одномодульной программе.
Рассмотрим
простейший пример:
mov
ax, Mem
где Mem - символическое описание некоторой ячейки памяти.
Одной из задач транслятора
является замена символического имени Mem на машинный адрес.
Транслятор не сможет этого сделать, пока не узнает, какой адрес будет присвоен
метке Mem.
Отсюда появляются два
прохода при трансляции. На первом проходе ищутся все символические имена и им
назначаются адреса. На втором проходе в тексте программы вместо символических
имен подставляются адреса.
Результатом первого прохода является таблица имен
переменных с их адресами.
Теперь представим себе
ситуацию, когда мы хотим составить единую программу из нескольких (минимум из
двух) модулей.
В каждом модуле могут существовать данные трех видов:
1) данные, описанные в этом
модуле, и используемые только этим модулем; с данными этого вида проблем не
возникает, ссылки на них организуются так, как было рассмотрено выше.
2) данные, описанные в этом
модуле, но которые могут быть доступны и в других модулях;
3) данные, в этом модуле не
описанные, но на которые этот модуль ссылается.
Простой пример.
Модуль
1 Модуль 2
M1 dw 0 M2 dw 0
mov ax, M1 mov ax, M2
mov ax, M2 mov
ax, M1
Здесь в модуле 1 описана
переменная М1, а используются переменные М1 и М2, последняя описана в другом
модуле.
В модуле 2 описана
переменная М2, а используются переменные М2 и М1, последняя описана в модуле 1.
В общем случае каждый модуль
может содержать ссылки на объекты из других модулей и содержать объекты, на
которые могут ссылаться другие модули.
Мы сказали, что результатом
первого прохода при трансляции является таблица соответствия имен переменных их адресам.
Так вот, результатом
трансляции одиночного модуля многомодульной программы являются две таблицы:
1) Таблица определения
символов, содержащая имена переменных, которые описаны в данном модуле и
доступны для других модулей. Эту таблицу называют таблицей внешних определений;
2) Таблица использования
символов, содержащая имена переменных, на которые встречаются ссылки в данном
модуле, но которые в нем не описаны. Эту таблицу называют таблицей внешних
ссылок.
При этом, как можно
догадаться, таблица внешних определений содержит кроме имен переменных еще и
адреса их относительно начала данного модуля.
А таблица внешних ссылок
содержит только имена переменных и не содержит никаких адресов этих переменных,
поскольку их адреса выделяются в других модулях.
Структуру объектного модуля многомодульной
программы можно изобразить следующим образом:
|
Заголовок |
Имя модуля |
Размер |
|
Таблица внешних ссылок |
… Внешний идентификатор … |
|
|
Таблица внешних определений |
... Идентификатор, Адрес_внутри_модуля ... |
|
|
Тело модуля |
... Адрес, Размер, Признак_перемещения, Код ... |
|
Данную таблицу можно
представить и в виде записей, использованных выше.
Признак_перемещения - это
параметр, который раньше имел два значения 1 или 0 - перемещаемый код или нет.
Теперь он становится более сложным:
0 - неперемещаемая информация;
1 - перемещаемая информация
внутренняя, т.е. перемещение относительно адреса загрузки данного модуля ;
< 0 - перемещаемая
информация внешняя (обычно модуль этого числа - это номер строки в таблице
внешних ссылок).
Аналогично тому, как трансляция
осуществляется в два прохода, на первом из которых производится формирование
таблицы соответствия имен и адресов, так и редактирование связей осуществляется
в два прохода. На первом проходе создается глобальная таблица внешних
идентификаторов, в которой таблицы внешних определений всех модулей сводятся в
единую таблицу следующего вида:
|
... Идентификатор Адрес ... |
где Адрес - это сумма адреса внутри модуля,
где описан идентификатор, и суммы размеров всех модулей, загружаемых перед
данным модулем.
Поясним последнее замечание. Предположим, что у нас
есть четыре модуля. Они будут компоноваться следующим образом:

Адрес D4 = 0 + Size1 + Size2 + Size3 + Offset D4
Результатом первого прохода
является полностью построенная глобальная таблица внешних идентификаторов. При
этом должно установиться полное соответствие между таблицами внешних ссылок и
таблицами внешних определений всех модулей. А именно, идентификатор,
появившийся в таблице внешних ссылок одного из модулей, должен обязательно
появиться в таблице внешних определений какого-нибудь другого модуля. Если
этого не произойдет, редактор связей выдаст ошибку типа "неопределенная
ссылка".
Второй проход в большей
части связан с перемещением кода в соответствие с данными глобальной таблицы.
Если признак перемещения
равен 1, т.е. перемещаемая информация - внутренняя, то величина перемещения
равна сумме размеров модулей, загружаемых перед данным модулем, как было
проиллюстрировано выше.
Если признак перемещения
меньше 0, т.е. перемещаемая информация - внешняя, то используется один из двух
способов:
1) в таблицу внешних ссылок
модуля записываются адреса идентификаторов, а обращение к данному
идентификатору в коде происходит по принципу косвенной адресации через
соответствующий номер строки в таблице; для этого номер строки в таблице и
указывался как значение признака перемещения;
Этот способ требует больших
затрат памяти, поскольку в исполняемом коде должна остаться таблица внешних
ссылок, и имеет невысокое быстродействие, поскольку реализуется через косвенную
адресацию. Преимуществом этого способа являются малые потери времени на
перемещение, поскольку при перемещении корректируется только таблица внешних
ссылок, но не код. Используется в интерпретирующих системах.
2) во все участки кода, подлежащие внешнему
перемещению, подставляются адреса соответствующих идентификаторов. Для
ускорения подстановки могут быть использованы списковые структуры: в строке
таблицы внешних ссылок находится указатель на начало списка из адресов кода,
куда надо подставить адрес идентификатора.

Если редактирование связей и
загрузка разделены во времени, то результатом редактирования является
загрузочный модуль, загрузка которого осуществляется так же, и как загрузка
одномодульной программы, рассмотренная выше.
Мы не расписывали алгоритмов
редактирования и загрузки, полагая, что из рассмотренных принципов они
становятся более или менее понятными. Ясно, что алгоритмы редактирования и
загрузки в большой степени включают в себя обработку кода путем сложения с
некоторыми величинами, значения которых определяются размерами модулей и
положением данных внутри модулей.
Рассмотренные методы
используются в основном для статического связывания, при котором из объектных
модулей создается загрузочный модуль, который содержит коды и данные всех
модулей и хранится в таком виде на диске. Далее рассмотрим динамическое
связывание, когда данные и коды модулей уже в готовом для исполнения виде
хранятся на диске раздельно, и связываются либо во время загрузки, либо во
время вызова.
Преимуществами статического связывания являются:
1) быстрое выполнение;
2) меньше модулей, т.к. все
они уже слинкованы в отдельный EXE-файл.
Недостатками статического связывания являются:
1) больший размер ЕХЕ-файла.
2) неразделяемый
код.
Преимуществами динамического связывания являются:
1) меньший размер ЕХЕ-файла;
2) разделяемый
код.
Недостатками динамического связывания являются:
1) более медленный запуск
из-за поиска и загрузки DLL во время выполнения;
2) больше шансов на ошибки, связанные с выполнением
соглашений между вызывающей программой и DLL.
8.5. Динамическое связывание
В начале рассмотрения
принципов динамического связывания напомню особенности реализации программ с
оверлейной структурой, поскольку такие программы являются как бы предвестником
программ с динамической компоновкой.
8.5.1. Организация
оверлейных программ
Главная цель организации
оверлейных программ состоит в экономии оперативной памяти за счет загрузки
различных модулей в одни и те же участки памяти по мере необходимости этих
модулей.
Часто оверлейные программы описываются
древовидными структурами. Рассмотрим пример.
┌───┐
│ А │ 1000
└─┬─┘1
┌────────────┼────────────┐
┌─┴─┐ ┌─┴─┐ ┌─┴─┐
│ B │ 500 │ C │ 1000 │ D │ 700
└─┬─┘2 └───┘3 └─┬─┘4
┌────┴────┐ ┌────┴────┐
┌─┴─┐ ┌─┴─┐ ┌─┴─┐ ┌─┴─┐
│ E │ 500 │ F │ 800 │ G │ 400 │ H │ 1000
└───┘5 └───┘6 └───┘7 └───┘8
Узлы дерева
называют секциями или сегментами.
Буквами
обозначены имена секций, числами - размеры секций.
Корневой сегмент (А - в
примере) загружается в начале выполнения программы и находится в памяти до
завершения ее выполнения. Остальные сегменты вызываются тогда, когда к ним
происходит обращение. Как правило, они записываются в виде, готовом к
исполнению, в специальный файл SEGFILE.
Секция А может вызывать секции B, C и D во
время выполнения. Секция B может вызывать секции E и F, а секция D - секции G и
H.
Секция В называется ОТЦОМ
секций E и F, а секция D - ОТЦОМ секций G и H.
Если секция А вызвала секцию
В, а та в свою очередь вызвала секцию F, то в памяти окажутся загруженными эти
перечисленные секции A, B, F.
Если секция А вызвала секцию
D, а та в свою очередь вызвала секцию G, то в памяти окажутся загруженными эти
перечисленные секции A, D, G.
Поскольку сегменты одного
уровня могут вызываться только из сегмента вышестоящего уровня, то они не могут
потребоваться одновременно и, соответственно, могут загружаться в одну и ту же
область памяти по мере необходимости.
Знание размеров сегментов
позволяет определить адреса их загрузки во время вызовов.
Предположим, что сегмент А
загружается с адреса 0000. Тогда следующая таблица дает начальные адреса
загрузки сегментов:
Сегмент Размер
Адрес загрузки
A 1000 0000
B 500 1000
C 1000 1000
D 700 1000
E 500 1500
F 800 1500
G 400 1700
H 1000 1700
Эта таблица показывает, что
все адреса могут быть определены рассмотренными методами раннего связывания,
отличие состоит в том, что "отец" может передать управление сегменту,
который в этот момент не находится в оперативной памяти.
Если программа - оверлейная,
то загрузчик добавляет к ней (точнее, к корневому, постоянно находящемуся в
памяти сегменту) специальный сегмент, называемый менеджером оверлеев - OVLMGR, и специальную таблицу
сегментов SEGTAB.
Команда обращения к
процедуре некоторой секции транслируется в команду обращения к строке таблицы SEGTAB, описывающей эту секцию.
Таблица SEGTAB содержит для каждого сегмента:
- начальный адрес загрузки сегмента;
- адрес точки входа в процедуру сегмента;
- адрес сегмента в файле SEGFILE;
- команду передачи управления (признак загружен сегмент в память или
нет).
Характер команды передачи
управления определяется тем, загружен ли сегмент в оперативную память или нет.
Если сегмент загружен, то
команда передачи управления - это команда перехода на точку входа в процедуру
сегмента.
Если сегмент не загружен, то
команда передачи управления - это команда перехода на точку входа специальной
процедуры менеджера оверлеев.
Эта специальная процедура выполняет следующие действия:
1) из файла SEGFILE
считывает
содержимое нужного сегмента и располагает его по заданному адресу;
2) корректирует команду
передачи управления данного сегмента в SEGTAB таким образом, чтобы
обращение к ней вызывало не процедуру менеджера оверлеев, а осуществляло
переход на требуемую точку входа процедуры сегмента (помечает сегмент как
загруженный);
3) корректирует команду
передачи управления сегмента, который затерт загрузкой нового вызванного
сегмента, на команду вызова менеджера оверлеев (помечает сегмент как
незагруженный);
4) повторяет действие 3) для
всех загруженных потомков затертого сегмента, т. е. помечает их как
незагруженные.
Ниже представлены карты
памяти в состояниях, когда уже загружены сегменты В и Е (строки 2 и 5 таблицы
помечены как загруженные, а повторный вызов В производится сразу через строку 2
таблицы ).
В это время происходит вызов сегмента С. Вызов
производится через процедуру OVLMGR. Сегмент С загружается на место В, строки 2 и 5
помечаются как незагруженные, а строка 3 помечается как загруженная.
┌──────────┐ ┌──────────┐
│ OVLMGR ├<─┐ ┌─────┤ OVLMGR ├<─┐
├──────────┤ │ │ ├──────────┤ │
┌─────>┤ /////// 2├──┼─┐ │ │ 2│ │
│ ├──────────┤ │ │ │ ├──────────┤ │
│ ┌─>┤ 3├──┘ │ │ ┌─>┤ /////// 3├──┘
│ │ ├──────────┤ │ │ │ ├──────────┤
│ │ │ 4│ │ │ │ │ 4│
│ │ ├──────────┤ │ │ │ ├──────────┤
│ │ │ /////// 5│ │ │ │ │ 5│
│ │ ├──────────┤ │ │ │ ├──────────┤
│ │ │ 6│ │ │ │ │ 6│
│ │ ├──────────┤ │ │ │ ├──────────┤
│ │ │ 7│ │ │ │ │ 7│
│ │ ├──────────┤ │ │ │ ├──────────┤
│ │ │ 8│ │ │ │ │ 8│
│ │ ├──────────┤ │ │ │ ├──────────┤
└───┼──┤ CALL B A│ │ │ │ │ A│
└──┤ CALL C │ │ │ └──┤ CALL C │
├──────────┤ │ │ ├──────────┤
│ B├<───┘ └────>┤ C│
├──────────┤ └──────────┘
│ E│
└──────────┘
8.5.2. Общая характеристика
динамического связывания
В этом случае загрузка и
связывание подпрограммы происходят в момент первого обращения к ней.
Механизм реализации
динамического связывания похож на реализацию оверлейной программы с учетом
того, что менеджер оверлеев и таблица сегментов превращаются в средство,
которое называется ДИНАМИЧЕСКИМ ЗАГРУЗЧИКОМ и которое является средством
операционной системы.
Краткое описание процесса
динамического связывания выглядит следующим образом.
При динамическом связывании
вместо выполнения команды СALL программа выполняет запрос к операционной системе. Параметром запроса
является символическое имя вызываемой подпрограммы. Операционная система по
своим внутренним таблицам определяет, загружена ли данная подпрограмма или нет.
Если подпрограмма не загружена, то она загружается, после чего операционная
система ее вызывает. Возврат из подпрограммы осуществляется в операционную
систему, которая в свою очередь возвращает управление программе.
Повторный вызов уже загруженной программы
осуществляется без перезагрузки. Динамический загрузчик может просто передать
на нее управление.

Как
уже говорилось, существует два вида динамического связывания:
- неявное связывание, на этапе загрузки программы
- явное связывание, на этапе выполнения программы.
Динамическая библиотека поставляется двумя файлами:
- .dll – собственно библиотека;
- .lib – заглушка библиотеки, предназначенная для
связи программы с библиотекой.
При неявном связывании
необходимо к проекту подсоединить файл .lib библиотеки, а вызываемую
функцию описать как импортируемую. Это делается специальной строкой следующего
вида:
extern "C" __declspec(dllimport) void Func_Hello();
В
исходном коде самой библиотеки функция декларируется строкой
extern
"C" __declspec(dllexport) void Func_Hello()
При явном связывании требуется загрузить
библиотеку вызовом:
HINSTANCE hDLL = AfxLoadLibrary("dll");
Затем
необходимо получить адрес точки входа в функцию. Это делается вызовом:
FARPROC
ProcAddr = GetProcAddress(hDLL,"Func_Hello");
Затем надо преобразовать тип возвращаемых
данных (FARPROC) преобразовать к типу
данных функции.
Например,
для описанной функции необходимо выполнить следующие действия:
1)
Описать
переменную: void (*Func)();
2)
Получить
ее значение: Func = (void(*)())ProcAddr;
3)
Воспользоваться
этой переменной, как именем функции: Func();
После использования библиотеки ее можно выгрузить вызовом
AfxFreeLibrary(hDLL);
8.5.3. Механизмы
динамического связывания
Представленное описание
поверхностное, на самом деле все гораздо сложнее. При этом акцент делается не
столько на загрузку по запросу во время выполнения, сколько на разделение
процедур и данных несколькими процессами.
Сначала
заметим, что разделение ресурсов в мультипрограммировании неизбежно. Если бы
каждый процесс имел собственную копию некоторого ресурса, системные накладные
расходы были бы очень велики. Они состояли бы из расходов на ввод-вывод при
загрузке копий и расходов памяти на хранение этих копий.
По
этой причине часто разделяется единственная копия ресурса в основной памяти.
Вопросы
разделения данных мы с вами подробно рассматривали в разделе “Параллельное
выполнение программ”. Критические секции – это и есть решение проблемы
разделения данных.
Здесь
рассмотрим вопросы разделения процедур.
На
заре программирования была необходимость с одной стороны, и считалось особым
шиком с другой стороны, писать программы, которые модифицируют собственные
коды.
В
современной практике модификация команд не является хорошим стилем. Этому
существуют две причины:
- Логика программы становится чрезвычайно запутанной
- Самоизменения не дают возможности разделять программу.
По этим причинам желательно устранить операции
запоминания в пределах областей программы.
Появился термин “чистые
процедуры”. Это процедуры, которые не модифицируют свои собственные команды и
локальные данные. Любая программа, которая является только выполняемой и
читающей, называется реентерабельной (повторно входимой), т.к. ее выполнение
может быть продолжено в любое время с уверенностью, что ничего не изменилось. Чистые
процедуры могут разделяться более чем одним процессом.
Изменяемые данные, связанные
с процессом, использующим чистую процедуру, должны храниться в отдельных
собственных областях. Эти данные включают обычно аргументы, адреса возврата,
промежуточные данные, результаты.
Наиболее удобным способом
доступа к переменной информации является доступ через базовые регистры,
указывающие на личную область во время выполнения.
Пример.
Пусть ARG – символическое
имя ячейки, содержащей некоторую переменную. [ARG] означает содержимое ARG.
Чтобы запомнить содержимое
регистра Ri в ARG, можно использовать
команду:
STO Ri, ARG;
[ARG] := [Ri];
Если данная команда является частью
разделяемой процедуры, то это может привести к некорректности, т.к. разные
процессы могут хранить разные данные в ячейке ARG.
Выходом
из положения будет вариант, при котором ARG является смещением внутри
собственной области любого процесса. А базовый адрес этой области хранится в
регистре Rb. При переходе от процесса к процессу базовый
регистр перегружается, а смещение остается неизменным.
Правильная
команда будет выглядеть так:
STO Ri,
ARG(Rb); [[Rb] + ARG] := [Ri];
Таким образом, регистры процессора, которые
запоминаются как часть вектора состояния процесса, обеспечивают простые
средства связывания чистых процедур с данными.
Итак,
мы видим, что внутренними ссылками легко управлять через базовый регистр.
Однако, внешние ссылки, например, имя разделяемой процедуры, должны быть
символическими. Только через символическое имя разделяемая процедура может быть
доступна процессам.
С
другой стороны, использование символической ссылки приводит к использованию
режима интерпретации, т.к. при каждом обращении символическую ссылку надо
преобразовывать в адрес.
Рациональным
вариантом был бы такой, при котором первое обращение данного процесса к
внешнему объекту выполнялось бы с интерпретацией, а все последующие обращения
выполнялись бы через адрес.
Каждая
разделяемая процедура состоит из трех частей:
- таблицы символов
- чистой программы
- секции связи.

Каждый процесс использует
собственную копию секции связи, когда использует процедуру. Адрес копии секции
связи хранится в регистре lp, так же, как адрес собственного стека хранится в регистре sp.
Таблица
символов содержит таблицу определений и таблицу использования символов.
Для
установления связи с внешним объектом применяется таблица использования
символов.
Пусть
процедура Р ссылается на слово Х в сегменте D. Это будет тем внешним
объектом, к которому обращается разделяемая процедура. При этом она может
обращаться к этому объекту в контексте нескольких процессов. Адрес этого
внешнего объекта в разных процессах разный, т.к. адрес – это смещение в таблице
сегментов данного процесса, а смещения наверняка разные.

Фрагмент чистой части Р показан ниже.

Здесь показано, что команда ADD [D, X] транслируется в команду ADD ldx, lp, т.е. в обращение к копии секции связи того процесса,
в контексте которого в данный момент выполняется процедура.
Т.е.
данные вычисляются через секцию связи. Когда процесс связывается с P, он
получает копию секции связи, а ее начальный адрес помещается в регистр lp. Т.е. все внешние ссылки доступны из Р через копию
секции связи.

Посмотрим
теперь, как происходит связывание данных с использованием перечисленных таблиц.

Когда
процесс начинает выбирать операнд [D, X] команды ADD,
происходит обращение к соответствующей строке копии секции связи.
Поскольку
при первом обращении флаг прерывания установлен, возникает внутреннее
прерывание, и управление передается программе, называемой установщиком связи.
Установщик
связи, по сути, корректирует копию секцию связи, заменяя idx на [d, x] и
сбрасывает флаг прерывания. Возможно, для этого первоначально потребуется
обращение к файловой системе для загрузки сегмента D.
После
этого происходит повторное обращение к копии секции связи.